Prieš naudodamiesi „Panda“ suvestine lentele, įsitikinkite, kad suprantate savo duomenis ir klausimus, kuriuos bandote išspręsti naudodamiesi „Pivot“ lentele. Naudodami šį metodą, galite pasiekti galingų rezultatų. Šiame straipsnyje mes išsamiau paaiškinsime, kaip sukurti sukimosi lentelę „pandas python“.
Skaityti duomenis iš „Excel“ failo
Atsisiuntėme „Excel“ maisto produktų pardavimo duomenų bazę. Prieš pradėdami diegimą, turite įdiegti keletą būtinų paketų, skirtų „Excel“ duomenų bazės failams skaityti ir rašyti. „Pycharm“ redaktoriaus skyriuje „Terminal“ įveskite šią komandą:
įdiekite xlwt openpyxl xlsxwriter xlrd
Dabar perskaitykite duomenis iš „Excel“ lapo. Importuokite reikalingas pandos bibliotekas ir pakeiskite savo duomenų bazės kelią. Tada paleisdami šį kodą, duomenis galite gauti iš failo.
importuoti pandas kaip pdimportuoti numerį kaip np
dtfrm = pd.read_excel ('C: / Vartotojai / DELL / Darbalaukis / foodsalesdata.xlsx ')
spausdinti (dtfrm)
Čia duomenys nuskaitomi iš „Food Sales Excel“ duomenų bazės ir perduodami į „dataframe“ kintamąjį.
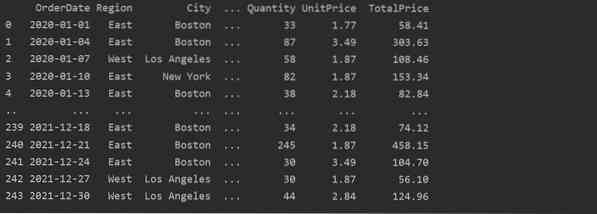
Sukurkite „Pivot“ lentelę naudodami „Pandas Python“
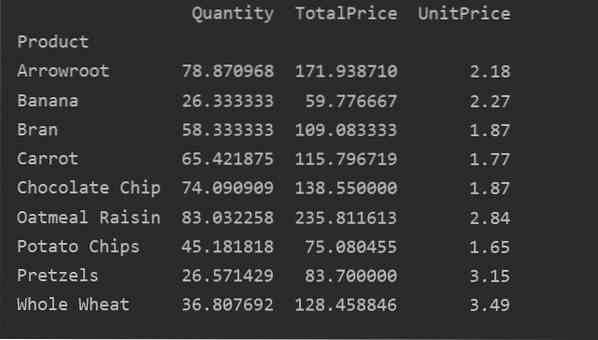
Žemiau mes sukūrėme paprastą sukamą lentelę naudodami maisto produktų duomenų bazę. Norėdami sukurti sukamą lentelę, reikia dviejų parametrų. Pirmasis yra duomenys, kuriuos mes perdavėme į duomenų rėmą, o kitas yra indeksas.
„Pivot“ duomenys rodyklėje
Indeksas yra suvestinės lentelės funkcija, leidžianti grupuoti duomenis pagal reikalavimus. Čia mes pasirinkome „Produktas“ kaip indeksą, kad sukurtume pagrindinę sukimosi lentelę.
importuoti pandas kaip pdimportuoti numerį kaip np
duomenų rėmelis = pd.read_excel ('C: / Vartotojai / DELL / Darbalaukis / foodsalesdata.xlsx ')
pivot_tble = pd.„pivot_table“ (duomenų rėmelis, rodyklė = [„Produktas“])
spausdinti („pivot_tble“)
Šis rezultatas rodomas paleidus aukščiau nurodytą šaltinio kodą:
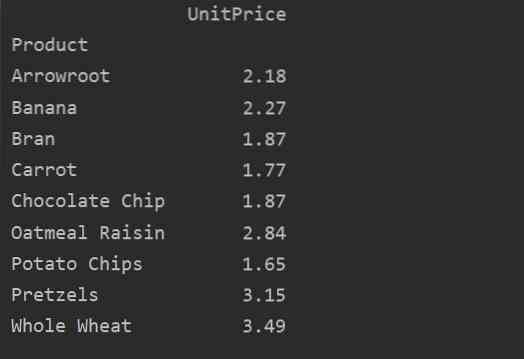
Aiškiai apibrėžkite stulpelius
Norėdami daugiau analizuoti savo duomenis, aiškiai apibrėžkite stulpelių pavadinimus su indeksu. Pavyzdžiui, rezultate norime parodyti vienintelę kiekvieno produkto „UnitPrice“. Šiuo tikslu pridėkite verčių parametrą į suvestinę lentelę. Šis kodas suteikia jums tą patį rezultatą:
importuoti pandas kaip pdimportuoti numerį kaip np
duomenų rėmelis = pd.read_excel ('C: / Vartotojai / DELL / Darbalaukis / foodsalesdata.xlsx ')
pivot_tble = pd.„pivot_table“ (duomenų rėmelis, rodyklė = „produktas“, vertės = „vieneto kaina“)
spausdinti („pivot_tble“)
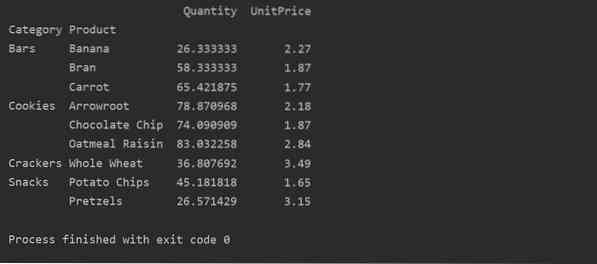
„Pivot“ duomenys su daugeliu indeksų
Duomenys gali būti grupuojami pagal daugiau nei vieną funkciją kaip indeksas. Naudodami kelių indeksų metodą, galite gauti tikslesnius duomenų analizės rezultatus. Pavyzdžiui, produktai priskiriami skirtingoms kategorijoms. Taigi galite rodyti „Produkto“ ir „Kategorijos“ indeksus su kiekvieno produkto „Kiekiu“ ir „Vieneto kaina“ taip:
importuoti pandas kaip pdimportuoti numerį kaip np
duomenų rėmelis = pd.read_excel ('C: / Vartotojai / DELL / Darbalaukis / foodsalesdata.xlsx ')
pivot_tble = pd.„pivot_table“ (duomenų kadras, rodyklė = ["Kategorija", "Produktas", vertės = ["Vieneto kaina", "Kiekis"])
spausdinti („pivot_tble“)
Agregavimo funkcijos taikymas „Pivot“ lentelėje
„Pivot“ lentelėje „aggfunc“ galima pritaikyti skirtingoms funkcijų vertėms. Gauta lentelė yra funkcijų duomenų apibendrinimas. Apibendrinimo funkcija taikoma jūsų grupės duomenims „pivot_table“. Pagal numatytuosius nustatymus agregavimo funkcija yra np.reiškia (). Tačiau, atsižvelgiant į vartotojo reikalavimus, skirtingoms duomenų funkcijoms gali būti taikomos skirtingos suvestinės funkcijos.
Pavyzdys:
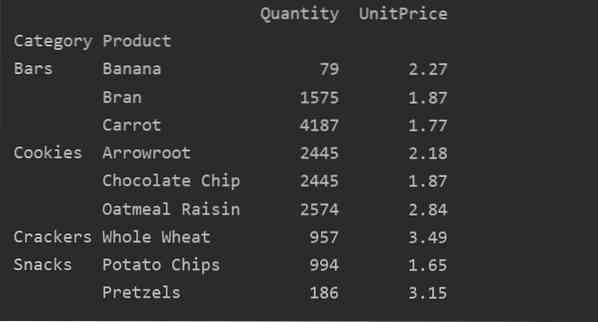
Šiame pavyzdyje pritaikėme suvestines funkcijas. Np.suma () naudojama funkcija „Kiekis“ ir np.funkcija „UnitPrice“ funkcija „mean ()“.
importuoti pandas kaip pdimportuoti numerį kaip np
duomenų rėmelis = pd.read_excel ('C: / Vartotojai / DELL / Darbalaukis / foodsalesdata.xlsx ')
pivot_tble = pd.„pivot_table“ (duomenų rėmelis, rodyklė = ["Kategorija", "Produktas"], aggfunc = 'Kiekis': np.suma, „UnitPrice“: np.reiškia)
spausdinti („pivot_tble“)
Pritaikę agregavimo funkciją skirtingoms funkcijoms, gausite tokį išvestį:
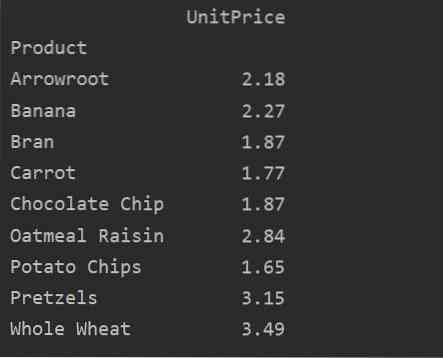
Naudodami vertės parametrą, taip pat galite pritaikyti agregavimo funkciją konkrečiai funkcijai. Jei nenurodysite objekto vertės, jis sujungia jūsų duomenų bazės skaitines savybes. Laikydamiesi nurodyto šaltinio kodo, galite pritaikyti agregavimo funkciją konkrečiai funkcijai:
importuoti pandas kaip pdimportuoti numerį kaip np
duomenų rėmelis = pd.read_excel ('C: / Vartotojai / DELL / Darbalaukis / foodsalesdata.xlsx ')
pivot_tble = pd.„pivot_table“ (duomenų kadras, rodyklė = ['produktas'], reikšmės = ['vieneto kaina'], aggfunc = np.reiškia)
spausdinti („pivot_tble“)
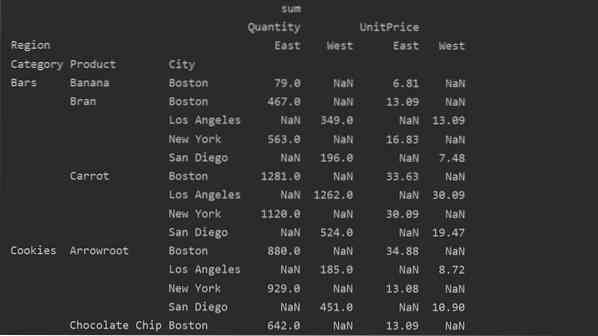
Skirtingi tarp Vertybių ir. Stulpeliai suvestinėje lentelėje
Vertės ir stulpeliai yra pagrindinis painus „pivot_table“ taškas. Svarbu pažymėti, kad stulpeliai yra neprivalomi laukai, viršų horizontaliai rodantys gautos lentelės vertes. Kaupimo funkcija aggfunc taikoma jūsų nurodytam reikšmių laukui.
importuoti pandas kaip pdimportuoti numerį kaip np
duomenų rėmelis = pd.read_excel ('C: / Vartotojai / DELL / Darbalaukis / foodsalesdata.xlsx ')
pivot_tble = pd.„pivot_table“ (duomenų rėmelis, rodyklė = ['Kategorija', 'Produktas,' Miestas '], reikšmės = [' Vieneto kaina ',' Kiekis '],
stulpeliai = ['Regionas'], aggfunc = [np.suma])
spausdinti („pivot_tble“)
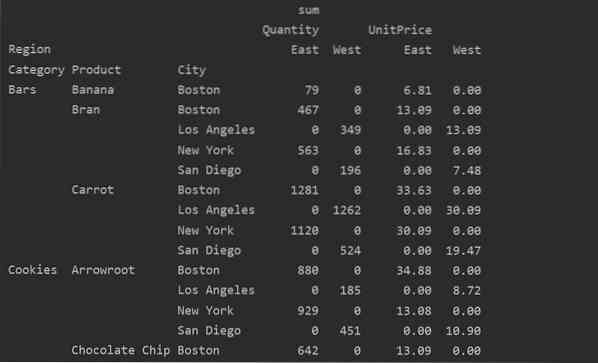
Trūkstamų duomenų tvarkymas „Pivot“ lentelėje
Trūkstamas reikšmes lentelėje „Pivot“ taip pat galite tvarkyti naudodami „fill_value“ Parametras. Tai leidžia pakeisti NaN reikšmes kažkokia nauja reikšme, kurią pateikiate užpildyti.
Pvz., Pašalinome visas nulines reikšmes iš pirmiau pateiktos gautos lentelės vykdydami šį kodą ir pakeisdami NaN reikšmes 0 visoje gautoje lentelėje.
importuoti pandas kaip pdimportuoti numerį kaip np
duomenų rėmelis = pd.read_excel ('C: / Vartotojai / DELL / Darbalaukis / foodsalesdata.xlsx ')
pivot_tble = pd.„pivot_table“ (duomenų rėmelis, rodyklė = ['Kategorija', 'Produktas,' Miestas '], reikšmės = [' Vieneto kaina ',' Kiekis '],
stulpeliai = ['Regionas'], aggfunc = [np.suma], užpildymo_vertė = 0)
spausdinti („pivot_tble“)
Filtravimas suvestinėje lentelėje
Sugeneravus rezultatą, filtrą galite pritaikyti naudodami standartinę duomenų rėmelio funkciją. Paimkime pavyzdį. Filtruokite tuos produktus, kurių „UnitPrice“ yra mažesnė nei 60. Joje rodomi tie produktai, kurių kaina yra mažesnė nei 60.
importuoti pandas kaip pdimportuoti numerį kaip np
duomenų rėmelis = pd.read_excel ('C: / Vartotojai / DELL / Darbalaukis / foodsalesdata.xlsx ', index_col = 0)
pivot_tble = pd.„pivot_table“ (duomenų rėmelis, indeksas = „produktas“, vertės = „vieneto kaina“, aggfunc = „suma“)
low_price = pivot_tble [pivot_tble ['UnitPrice'] < 60]
spausdinti (maža kaina)

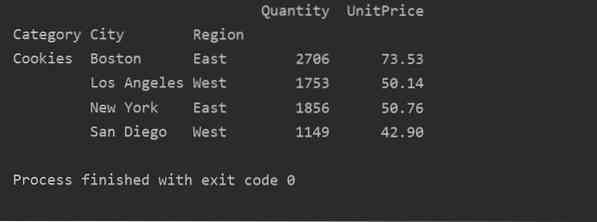
Naudodami kitą užklausos metodą, galite filtruoti rezultatus. Pavyzdžiui, mes filtravome slapukų kategoriją pagal šias funkcijas:
importuoti pandas kaip pdimportuoti numerį kaip np
duomenų rėmelis = pd.read_excel ('C: / Vartotojai / DELL / Darbalaukis / foodsalesdata.xlsx ', index_col = 0)
pivot_tble = pd.„pivot_table“ (duomenų kadras, rodyklė = ["Kategorija", "Miestas", "Regionas"], reikšmės = ["Vieneto kaina", "Kiekis"], aggfunc = np.suma)
pt = sukamasis_tabulas.užklausa ('Kategorija == ["Slapukai"]')
spausdinti (pt)
Išvestis:
Vizualizuokite „Pivot“ lentelės duomenis
Norėdami vizualizuoti suvestinės lentelės duomenis, atlikite šį metodą:
importuoti pandas kaip pdimportuoti numerį kaip np
importuoti matplotlib.pyplotas kaip plt
duomenų rėmelis = pd.read_excel ('C: / Vartotojai / DELL / Darbalaukis / foodsalesdata.xlsx ', index_col = 0)
pivot_tble = pd.„pivot_table“ (duomenų rėmelis, rodyklė = ["Kategorija", "Produktas", vertės = ["Vieneto kaina"])
pivot_tble.siužetas (natūra = 'baras');
plt.Rodyti()
Pirmiau pateiktoje vizualizacijoje parodėme skirtingų produktų vieneto kainą kartu su kategorijomis.

Išvada
Mes ištyrėme, kaip galite sukurti „Pivot“ lentelę iš duomenų kadro naudodami „Pandas python“. „Pivot“ lentelė leidžia generuoti išsamią duomenų rinkinių įžvalgą. Mes matėme, kaip sukurti paprastą „pivot“ lentelę naudojant kelis indeksus ir pritaikyti filtrus ant „pivot“ lentelių. Be to, mes taip pat parodėme braižyti suvestinės lentelės duomenis ir užpildyti trūkstamus duomenis.


