Apache Solr
„Apache Solr“ yra viena iš populiariausių „NoSQL“ duomenų bazių, kuri gali būti naudojama duomenims saugoti ir pateikti užklausas beveik realiuoju laiku. Jis pagrįstas „Apache Lucene“ ir parašytas „Java“. Kaip ir „Elasticsearch“, jis palaiko duomenų bazių užklausas per REST API. Tai reiškia, kad mes galime naudoti paprastus HTTP skambučius ir naudoti HTTP metodus, tokius kaip GET, POST, PUT, DELETE ir kt. prieigai prie duomenų. Tai taip pat suteikia galimybę gauti XML arba JSON formą per REST API.
Šioje pamokoje mes ištirsime, kaip įdiegti „Apache Solr“ į „Ubuntu“ ir pradėti dirbti su juo naudojant pagrindinį duomenų bazių užklausų rinkinį.
„Java“ diegimas
Norėdami įdiegti „Solr“ į „Ubuntu“, pirmiausia turime įdiegti „Java“. „Java“ gali būti neįdiegta pagal numatytuosius nustatymus. Mes galime tai patikrinti naudodami šią komandą:
java -versijaVykdydami šią komandą, gauname šį išvestį: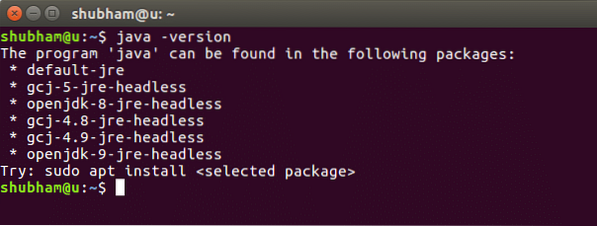
Dabar mes įdiegsime „Java“ savo sistemoje. Norėdami tai padaryti, naudokite šią komandą:
sudo add-apt-repository ppa: webupd8team / javasudo apt-get atnaujinimas
sudo apt-get install oracle-java8-installer
Vykdžius šias komandas, mes galime dar kartą patikrinti, ar „Java“ jau įdiegta, naudodami tą pačią komandą.
Diegiama „Apache Solr“
Dabar pradėsime nuo „Apache Solr“ įdiegimo, kuris iš tikrųjų yra tik kelių komandų klausimas.
Norėdami įdiegti „Solr“, turime žinoti, kad „Solr“ neveikia ir neveikia savarankiškai, o norint paleisti, pavyzdžiui, „Jetty“ arba „Tomcat Servlet“ konteinerius, reikia „Java Servlet“ konteinerio. Šioje pamokoje naudosime „Tomcat“ serverį, tačiau „Jetty“ naudojimas yra gana panašus.
Geras dalykas, susijęs su „Ubuntu“, yra tai, kad jame yra trys paketai, kuriais galima lengvai įdiegti ir paleisti „Solr“. Jie yra:
- solr-bendras
- solr-runis
- solr-prieplauka
Apibūdina tai, kad „solr-common“ reikia abiem konteineriams, o „solr-moliukas“ reikalingas „Jetty“, o „solr-tomcat“ - tik „Tomcat“ serveriui. Kadangi jau įdiegėme „Java“, „Solr“ paketą galime atsisiųsti naudodami šią komandą:
sudo wget http: // www-eu.apache.org / dist / lucene / solr / 7.2.1 / solr-7.2.1.užtrauktukasKadangi šis paketas atneša daug paketų, įskaitant „Tomcat“ serverį, tai gali užtrukti kelias minutes, kol viską atsisiųsite ir įdiegsite. Atsisiųskite naujausią „Solr“ failų versiją iš čia.
Baigę diegimą, failą galime išpakuoti naudodami šią komandą:
atsegti -q solr-7.2.1.užtrauktukasDabar pakeiskite savo katalogą į ZIP failą ir pamatysite šiuos failus:
Paleidžiamas „Apache Solr Node“
Dabar, kai atsisiuntėme „Apache Solr“ paketus į savo kompiuterį, mes galime padaryti daugiau kaip kūrėjai iš mazgo sąsajos, todėl mes paleisime „Solr“ mazgo egzempliorių, kuriame mes iš tikrųjų galime kurti kolekcijas, saugoti duomenis ir pateikti užklausas.
Norėdami pradėti grupių sąranką, vykdykite šią komandą:
./ bin / solr start -e debesisSu šia komanda matysime tokį išėjimą: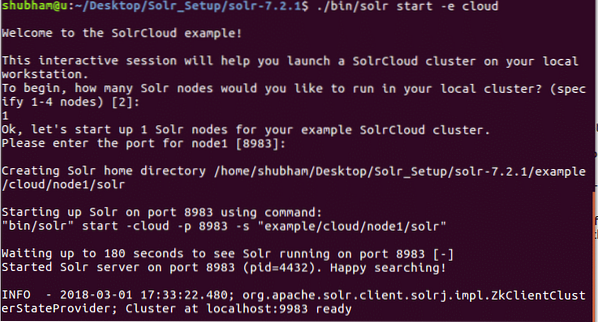
Bus užduota daug klausimų, bet mes sukonfigūruosime vieno mazgo „Solr“ grupę su visa numatytąja konfigūracija. Kaip parodyta paskutiniame etape, „Solr“ mazgo sąsaja bus pasiekiama:
kur 8983 yra numatytasis mazgo prievadas. Apsilankę aukščiau esančiame URL pamatysime „Node“ sąsają: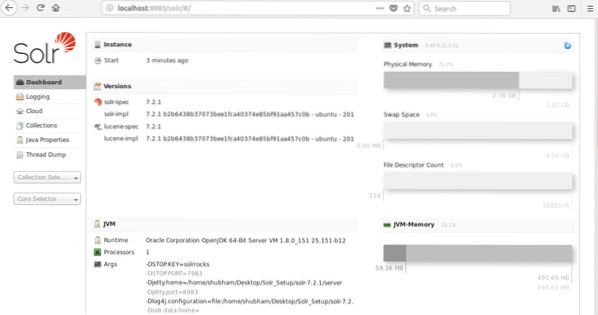
„Solr“ kolekcijų naudojimas
Dabar, kai mūsų mazgo sąsaja veikia ir veikia, galime sukurti kolekciją naudodami komandą:
./ bin / solr create_collection -c linux_hint_collectionir pamatysime tokį išėjimą:
Kol kas venkite įspėjimų. Kolekciją galime pamatyti ir „Node“ sąsajoje:
Dabar galime pradėti apibrėždami schemą „Apache Solr“ pasirinkdami schemos skyrių: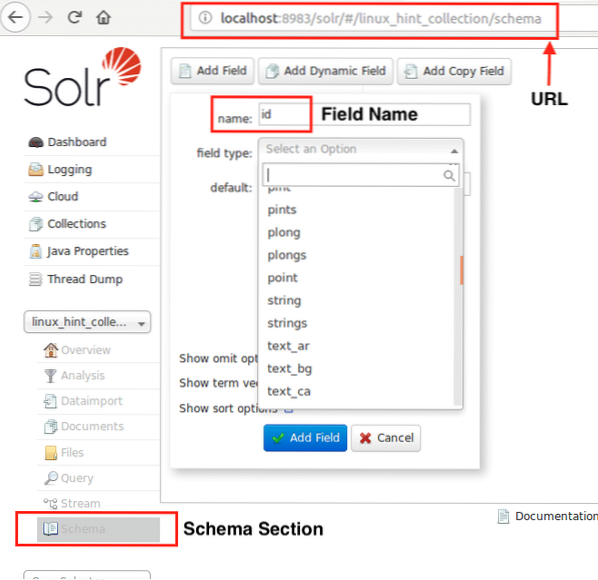
Dabar galime pradėti įterpti duomenis į savo kolekcijas. Į savo kolekciją įdėkime JSON dokumentą čia:
curl -X POST -H 'Turinio tipas: programa / JSON'"http: // localhost: 8983 / solr / linux_hint_collection / update / json / docs" --data-dvejetainis "
„id“: „iduye“,
"name": "Shubham"
Pamatysime sėkmingą atsakymą prieš šią komandą:
Kaip paskutinę komandą pažiūrėkime, kaip mes galime gauti visus „Solr“ kolekcijos duomenis:
Pamatysime tokį išėjimą:

