„Apache Spark“ yra duomenų analizės įrankis, kuris gali būti naudojamas apdorojant duomenis iš HDFS, S3 ar kitų atminties duomenų šaltinių. Šiame įraše mes įdiegsime „Apache Spark“ „Ubuntu 17“.10 mašina.
„Ubuntu“ versija
Šiame vadove naudosime „Ubuntu 17“ versiją.10 (GNU / Linux 4.13.0-38-bendras x86_64).
„Apache Spark“ yra „Hadoop“ ekosistemos, skirtos didiesiems duomenims, dalis. Pabandykite įdiegti „Apache Hadoop“ ir su juo padarykite programos pavyzdį.
Esamų paketų atnaujinimas
Norint pradėti diegti „Spark“, būtina atnaujinti savo mašiną naujausiais programinės įrangos paketais. Tai galime padaryti:
sudo apt-get update && sudo apt-get -y dist-upgradeKadangi „Spark“ yra pagrįstas „Java“, turime jį įdiegti savo kompiuteryje. Mes galime naudoti bet kurią „Java“ versiją virš „Java 6“. Čia mes naudosime „Java 8“:
sudo apt-get -y įdiekite openjdk-8-jdk-headlessAtsisiunčiami „Spark“ failai
Dabar visi reikalingi paketai yra mūsų mašinoje. Esame pasirengę atsisiųsti reikalingus „Spark TAR“ failus, kad galėtume pradėti juos nustatyti ir paleisti programos pavyzdį su „Spark“.
Šiame vadove mes įdiegsime „Spark v2“.3.0 galima čia:
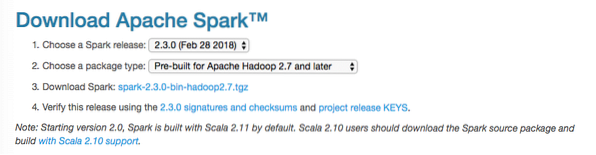
„Spark“ atsisiuntimo puslapis
Atsisiųskite atitinkamus failus naudodami šią komandą:
wget http: // www-us.apache.org / dist / spark / spark-2.3.0 / kibirkštis-2.3.0-bin-hadoop2.7.tgzAtsižvelgiant į tinklo greitį, tai gali užtrukti kelias minutes, nes failas yra didelis:
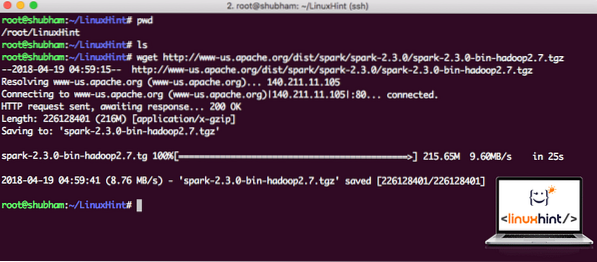
Atsisiunčiama „Apache Spark“
Dabar, kai turime atsisiųstą TAR failą, galime išskleisti dabartiniame kataloge:
degutas xvzf spark-2.3.0-bin-hadoop2.7.tgzTai užtruks kelias sekundes dėl didelio archyvo failo dydžio:
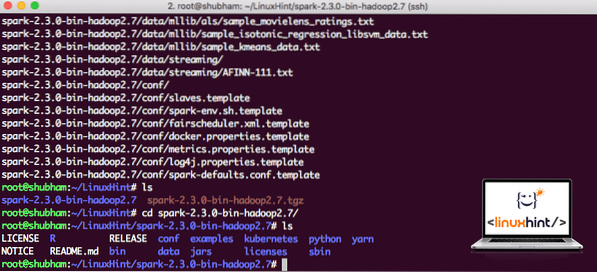
Nearchyvuoti failai „Spark“
Ateityje atnaujinant „Apache Spark“, tai gali sukelti problemų dėl kelio naujinių. Šių problemų galima išvengti sukūrus „Spark“ nuorodą. Paleiskite šią komandą, kad sukurtumėte nuorodą:
ln -s kibirkštis-2.3.0-bin-hadoop2.7 kibirkštisKibirkšties pridėjimas prie kelio
Norėdami vykdyti „Spark“ scenarijus, mes dabar jį pridėsime prie kelio. Norėdami tai padaryti, atidarykite failą bashrc:
vi ~ /.bashrcPridėkite šias eilutes prie pabaigos .„bashrc“ failą, kad kelyje būtų „Spark“ vykdomojo failo kelias:
SPARK_HOME = / „Linux“ patarimas / kibirkštiseksportuoti PATH = $ SPARK_HOME / šiukšliadėžė: $ PATH
Dabar failas atrodo taip:
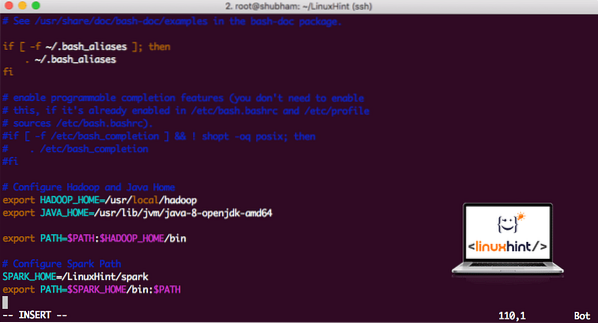
„Spark“ pridėjimas prie PATH
Norėdami suaktyvinti šiuos pakeitimus, paleiskite šią bashrc failo komandą:
šaltinis ~ /.bashrcPaleisti „Spark Shell“
Dabar, kai esame tiesiai už kibirkščių katalogo, paleiskite šią komandą, kad atidarytumėte „apark“ apvalkalą:
./ kibirkštis / šiukšliadėžė / kibirkštisPamatysime, kad „Spark“ apvalkalas yra atidarytas dabar:
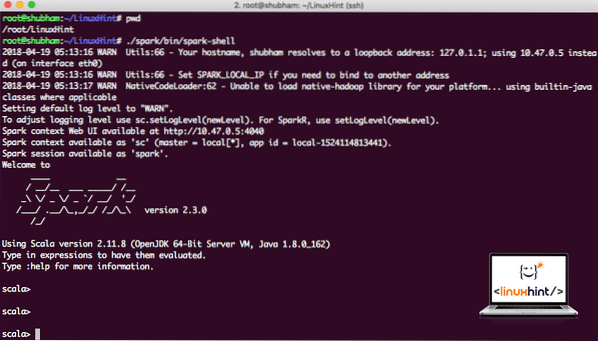
Paleidimas „Spark shell“
Pultelyje matome, kad „Spark“ taip pat atidarė interneto konsolę 404 prievade. Apsilankykime:
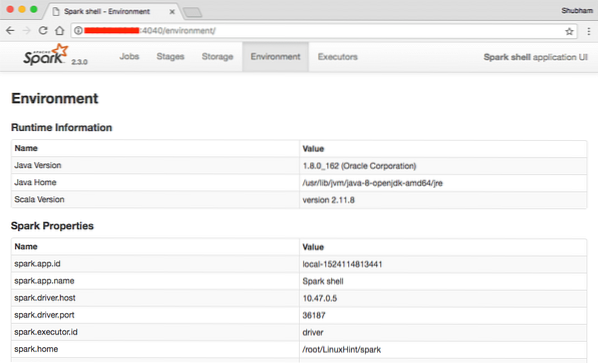
„Apache Spark“ interneto konsolė
Nors veiksime pačioje konsolėje, žiniatinklio aplinka yra svarbi vieta, į kurią reikia atkreipti dėmesį, kai atliekate sunkius „Spark“ darbus, kad žinotumėte, kas vyksta kiekviename jūsų vykdomame „Spark“ darbe.
Patikrinkite „Spark shell“ versiją naudodami paprastą komandą:
sc.versijaMes grįšime kažką panašaus:
res0: Stygos = 2.3.0„Scala“ pavyzdžio „Spark“ naudojimas
Dabar mes sukursime „Word Counter“ programos pavyzdį su „Apache Spark“. Norėdami tai padaryti, pirmiausia įkelkite teksto failą į „Spark Context“ ant „Spark“ apvalkalo:
scala> var Duomenys = sc.textFile ("/ root / LinuxHint / spark / README.md ")Duomenys: org.apache.kibirkštis.rdd.RDD [String] = / root / LinuxHint / spark / README.md MapPartitionsRDD [1] at textFile adresu: 24
scala>
Dabar faile esantis tekstas turi būti suskirstytas į žetonus, kuriuos „Spark“ gali valdyti:
scala> var tokens = duomenys.„flatMap“ (s => s.padalinti (""))žetonai: org.apache.kibirkštis.rdd.RDD [String] = MapPartitionsRDD [2] „flatMap“ adresu: 25
scala>
Dabar inicijuokite kiekvieno žodžio skaičių iki 1:
scala> var žetonai_1 = žetonai.žemėlapis (s => (s, 1))žetonai_1: org.apache.kibirkštis.rdd.RDD [(String, Int)] = MapPartitionsRDD [3] žemėlapyje: 25
scala>
Galiausiai apskaičiuokite kiekvieno failo žodžio dažnumą:
var sum_each = žetonai_1.reducByKey ((a, b) => a + b)Laikas pažvelgti į programos išvestį. Surinkite žetonus ir jų skaičių:
scala> sum_each.rinkti ()res1: Masyvas [(String, Int)] = Masyvas ((paketas, 1), (Už, 3), (Programos, 1), (apdorojimas.,1), (Nes, 1), (The, 1), (puslapis] (http: // kibirkštis.apache.org / dokumentacija.HTML).,1), (klasteris.,1), (its, 1), ([run, 1), (than, 1), (API, 1), (have, 1), (Try, 1), (computation, 1), (through, 1) ), (keli, 1), (tai, 2), (grafikas, 1), (avilys, 2), (saugykla, 1), (["Nurodykite, 1), (Iki, 2), (" verpalai "). , 1), (Vieną kartą, 1), (["Naudinga, 1), (pageidautina, 1), (SparkPi, 2), (variklis, 1), (versija, 1), (byla, 1), [dokumentacija ,, 1), (apdorojimas ,, 1), (the, 24), (yra, 1), (sistemos.,1), (parametrai, 1), (ne, 1), (skirtingi, 1), (nuoroda, 2), (interaktyvus, 2), (R ,, 1), (pateiktas.,1), (if, 4), (build, 4), (when, 1), (be, 2), (Testai, 1), (Apache, 1), (thread, 1), (programos ,, 1 ) (įskaitant 4), (./ bin / run-example, 2), (Kibirkštis.,1), (pakuotė.,1), (1000).skaičius (), 1), (1 versijos), (HDFS, 1), (D…
scala>
Puiku! Mes galėjome paleisti paprastą „Word Counter“ pavyzdį naudodami „Scala“ programavimo kalbą su sistemoje jau esančiu teksto failu.
Išvada
Šioje pamokoje apžvelgėme, kaip galime įdiegti „Apache Spark“ ir pradėti jį naudoti „Ubuntu 17“.10 mašiną ir taip pat paleiskite pavyzdinę programą.
Skaitykite daugiau „Ubuntu“ pagrįstų įrašų čia.


