Šioje pamokoje tai ir ketiname padaryti. Mes sužinosime, kaip galima išskleisti skirtingų HTML žymų reikšmes, taip pat nepaisysime numatytojo šio modulio funkcijų, kad pridėtume tam tikrą savo logiką. Tai padarysime naudodami HTMLParser klasėje „Python“ HTML.analizatorius modulis. Pažiūrėkime, kaip veikia kodas.
Pažvelgus į HTMLParser klasę
Norėdami išanalizuoti HTML tekstą „Python“, galime pasinaudoti HTMLParser klasė HTML.analizatorius modulis. Pažvelkime į klasės varžybas HTMLParser klasė:
klasės html.analizatorius.HTMLParser (*, convert_charrefs = True)The convert_charrefs lauke, jei nustatyta į „True“, visos simbolių nuorodos bus konvertuotos į jų „Unicode“ atitikmenis. Tik scenarijus / stilius elementai nėra konvertuojami. Dabar pabandysime suprasti ir kiekvieną šios klasės funkciją, kad geriau suprastume, ką daro kiekviena funkcija.
- hand_startendtag Tai yra pirmoji funkcija, kuri suveikia, kai HTML eilutė perduodama klasės egzemplioriui. Kai tekstas pasiekia čia, valdiklis perduodamas kitoms klasės funkcijoms, kurios susiaurėja iki kitų eilutės žymių. Tai taip pat aišku šios funkcijos apibrėžime: def hand_startendtag (self, tag, attrs):
savarankiškai.hand_starttag (tag, attrs)
savarankiškai.rankenos_pavadinimas (žyma) - hand_starttag: Šis metodas tvarko gautų duomenų pradžios žymą. Jo apibrėžimas yra toks, kaip parodyta žemiau: def hand_starttag (self, tag, attrs):
praeiti - rankenos_pavadinimas: Šis metodas tvarko gaunamų duomenų pabaigos žymą: def hand_endtag (self, tag):
praeiti - rankena_charref: Šis metodas tvarko gaunamų duomenų simbolių nuorodas. Jo apibrėžimas yra toks, kaip parodyta žemiau: def hand_charref (pats, vardas):
praeiti - rankenos_patybėref: Ši funkcija tvarko subjekto nuorodas jai perduotame HTML: def hand_entityref (savarankiškai, vardas):
praeiti - rankenos_duomenys: Tai yra funkcija, kurioje atliekamas tikras darbas išgaunant reikšmes iš HTML žymių ir perduodant su kiekviena žyma susijusius duomenis. Jo apibrėžimas yra toks, kaip parodyta žemiau: def hand_data (savarankiškai, duomenys):
praeiti - rankena_komentaras: Naudodamiesi šia funkcija, taip pat galime gauti komentarų, pridėtų prie HTML šaltinio: def hand_comment (savęs, duomenų):
praeiti - rankena_pi: Kadangi HTML taip pat gali turėti apdorojimo instrukcijas, tai yra funkcija, kur jos apibrėžimas yra toks, kaip parodyta žemiau: def hand_pi (savarankiškai, duomenys):
praeiti - rankena_decl: Šis metodas tvarko deklaracijas HTML, jo apibrėžimas pateikiamas taip: def hand_decl (self, decl):
praeiti
Klasės HTMLParser poklasis
Šiame skyriuje mes klasifikuosime HTMLParser klasę ir apžvelgsime kai kurias funkcijas, kurios yra iškviečiamos, kai HTML duomenys perduodami klasės egzemplioriui. Parašykime paprastą scenarijų, kuris atliktų visa tai:
iš html.analizatoriaus importas HTMLParserklasės „LinuxHTMLParser“ (HTMLParser):
def rank_starttag (savarankiškai, žyma, attrai):
spausdinti ("Pradėta žyma įvyko:", žyma)
def hand_endtag (savarankiškai, žyma):
spausdinti ("Aptikta pabaigos žyma:", žyma)
def rank_data (savęs, duomenų):
spausdinti ("Rasti duomenys:", duomenys)
analizatorius = LinuxHTMLParser ()
analizatorius.maitinti("
"
„Python“ HTML analizavimo modulis
„)
Štai ką mes grąžiname naudodami šią komandą:
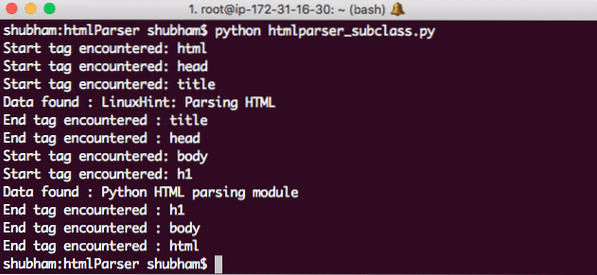
„Python HTMLParser“ poklasis
HTMLParser funkcijos
Šiame skyriuje dirbsime su įvairiomis HTMLParser klasės funkcijomis ir nagrinėsime kiekvieno iš jų funkcionalumą:
iš html.analizatoriaus importas HTMLParseriš html.subjektai importuoja name2cepepoint
klasės „LinuxHint_Parse“ (HTMLParser):
def rank_starttag (savarankiškai, žymos, attrai):
spausdinti ("Pradėti žymą:", žyma)
už attr attrus:
spausdinti ("attr:", attr)
def hand_endtag (savarankiškai, žyma):
spausdinti ("End tag:", tag)
def rank_data (savęs, duomenų):
spausdinti ("Duomenys:", duomenys)
def rank_komentaras (savęs, duomenų):
spausdinti ("Komentaras:", duomenys)
def rankos_entityrefas (pats, vardas):
c = chr (vardas2 kodo taškas [vardas])
spausdinti („Pavadinta ent:“, c)
def rankos_charrefas (pats, vardas):
jei vardas.startswith ('x'):
c = chr (int (vardas [1:], 16))
Kitas:
c = chr (int (vardas))
spausdinti („Num ent:“, c)
def rank_decl (savęs, duomenų):
spausdinti ("Decl:", duomenys)
analizatorius = LinuxHint_Parse ()
Vykdydami įvairius skambučius, pateikime atskirus HTML duomenis šiam egzemplioriui ir pažiūrėkime, kokį išvestį generuoja šie skambučiai. Pradėsime nuo paprasto DOCTYPE eilutė:
analizatorius.maitinti('"" http: // www.w3.org / TR / html4 / griežtas.dtd "> ')Štai ką mes grįšime su šiuo skambučiu:
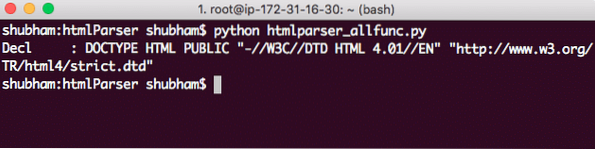
DOCTYPE eilutė
Išbandykime vaizdo žymą ir pažiūrėkime, kokius duomenis ji ištraukia:
analizatorius.maitinti(' „)
„) Štai ką mes grįšime su šiuo skambučiu:

HTMLParser vaizdo žyma
Tada pabandykime, kaip scenarijaus žyma veikia su „Python“ funkcijomis:
analizatorius.maitinti('„)analizatorius.maitinti('„)
analizatorius.sklaidos kanalas ('# python color: green')
Štai ką mes grįšime su šiuo skambučiu:

Scenarijaus žyma HTMLparne
Galiausiai mes taip pat perduodame komentarus HTMLParser skyriui:
analizatorius.maitinti('""„)
Štai ką mes grįšime su šiuo skambučiu:

Analizuojami komentarai
Išvada
Šioje pamokoje mes apžvelgėme, kaip mes galime analizuoti HTML, naudodami „Python“ savo HTMLParser klasę be jokios kitos bibliotekos. Mes galime lengvai modifikuoti kodą, kad HTML duomenų šaltinis būtų pakeistas į HTTP klientą.
Skaitykite daugiau „Python“ pagrįstų įrašų čia.


