Visuotinis internetas yra visa apimantis ir galutinis visų turimų duomenų šaltinis. Sparti interneto plėtra per pastaruosius tris dešimtmečius nebuvo precedento. Todėl žiniatinklis kiekvieną dieną kaupiamas su šimtais terabaitų duomenų.
Visi šie duomenys tam tikram žmogui turi tam tikrą vertę. Pavyzdžiui, jūsų naršymo istorija turi reikšmės socialinės žiniasklaidos programoms, nes jos ją naudoja norėdami suasmeninti jums rodomas reklamas. Dėl šių duomenų taip pat yra didelė konkurencija; keli MB daugiau kai kurių duomenų gali suteikti verslui reikšmingą pranašumą prieš jų konkurenciją.
Duomenų gavyba naudojant „Python“
Norėdami padėti tiems iš jūsų, kurie dar nesinaudojo duomenų kaupimu, parengėme šį vadovą, kuriame parodysime, kaip nukopijuoti duomenis iš žiniatinklio naudojant „Python“ ir „Beautiful sriubų biblioteką“.
Darome prielaidą, kad jau esate gerai susipažinę su „Python“ ir HTML, nes dirbsite su abiem vadovaudamiesi šio vadovo instrukcijomis.
Būkite atsargūs, kokiose svetainėse bandote naujai įgytus duomenų gavybos įgūdžius, nes daugelis svetainių mano, kad tai įkyru ir žino, kad tai gali turėti įtakos.
Bibliotekų diegimas ir paruošimas
Dabar naudosime dvi bibliotekas, kurias naudosime: „python“ užklausų biblioteka turinio įkėlimui iš tinklalapių ir „Beautiful Soup“ biblioteka - tikram proceso šukavimui. Nepamirškite, kad yra „BeautifulSoup“ alternatyvų, ir jei esate susipažinę su bet kuriuo iš šių dalykų, drąsiai naudokite juos: „Scrappy“, „Mechanize“, „Selenium“, „Portia“, „kimono“ ir „ParseHub“.
Užklausų biblioteką galima atsisiųsti ir įdiegti naudojant komandą pip, kaip nurodyta toliau:
# pip3 diegimo užklausų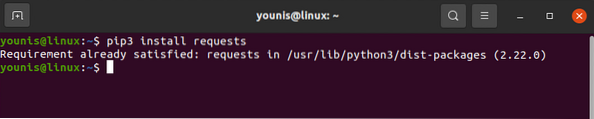
Užklausų biblioteka turėtų būti įdiegta jūsų įrenginyje. Panašiai atsisiųskite „BeautifulSoup“:
# pip3 įdiekite beautifulsoup4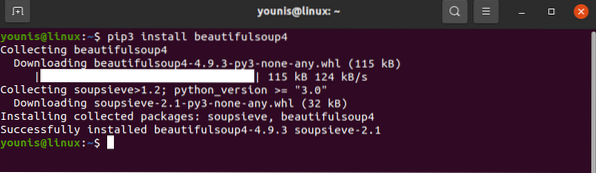
Tuo mūsų bibliotekos yra pasirengusios atlikti tam tikrus veiksmus.
Kaip minėta aukščiau, užklausų bibliotekoje nėra daug naudos, išskyrus tai, kad iš tinklalapių turinio yra gaunama. „BeautifulSoup“ bibliotekoje ir užklausų bibliotekose yra vieta kiekviename scenarijuje, kurį ketinate rašyti, ir jie turi būti importuojami prieš kiekvieną taip:
$ importavimo užklausos$ iš „bs4“ importuokite „BeautifulSoup“ kaip bs
Tai prideda prašomą raktinį žodį prie vardų srities, nurodydama „Python“ raktinio žodžio reikšmę, kai tik paraginama jį naudoti. Tas pats nutinka ir raktiniam žodžiui „bs“, nors čia mes turime pranašumą priskirti paprastesnį raktinį žodį „BeautifulSoup“.
tinklalapis = užklausos.gauti (URL)Aukščiau pateiktas kodas gauna tinklalapio URL ir sukuria iš jo tiesioginę eilutę, išsaugodamas ją kintamajame.
$ webcontent = tinklalapis.turinysAukščiau pateikta komanda nukopijuoja tinklalapio turinį ir priskiria jį kintamajam žiniatinklio turiniui.
Tai atlikome su užklausų biblioteka. Liko tik pakeisti užklausų bibliotekos parinktis į „BeautifulSoup“ parinktis.
$ htmlcontent = bs (žiniatinklio turinys, „html.analizatorius “)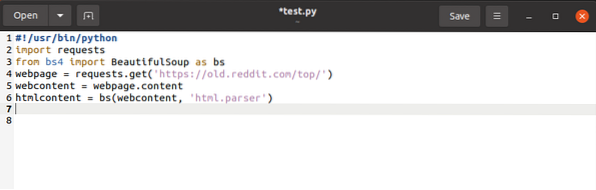
Tai analizuoja užklausos objektą ir paverčia jį skaitomais HTML objektais.
Pasirūpinę tuo, mes galime pereiti prie tikrojo grandymo antgalio.
Žiniatinklio grandymas naudojant „Python“ ir „BeautifulSoup“
Pereikime ir pažiūrėkime, kaip galime nuskaityti HTML duomenų objektus naudodami „BeautifulSoup“.
Norėdami iliustruoti pavyzdį, kol paaiškinsime dalykus, dirbsime su šiuo HTML fragmentu:
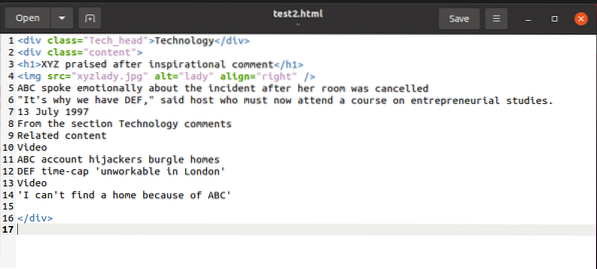
Šio fragmento turinį galime pasiekti naudodami „BeautifulSoup“ ir naudoti jį HTML turinio kintamajame, kaip nurodyta toliau:
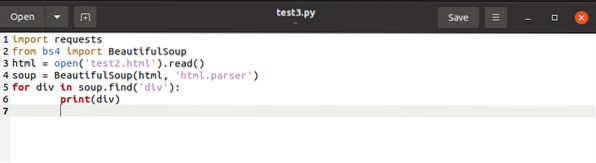
Aukščiau pateiktas kodas ieško visų pavadintų žymų
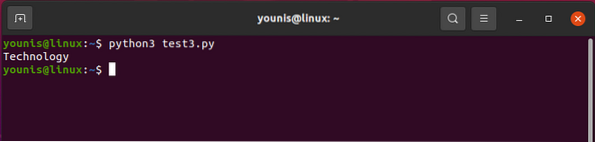
Norėdami tuo pat metu išsaugoti pavadintas žymas
į sąrašą mes išdavėme galutinį kodą taip: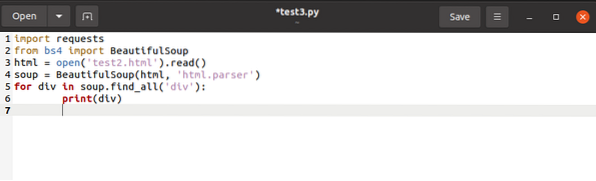
Išvestis turėtų grįžti taip:
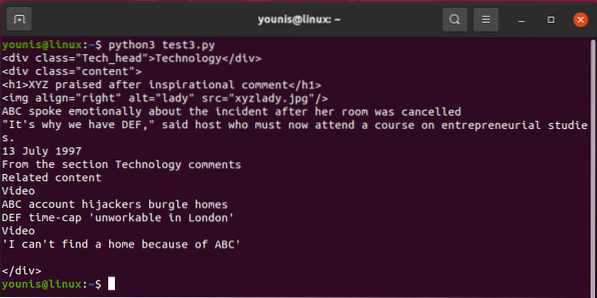
Iškviesti vieną iš
Dabar galime pamatyti, kaip išsirinkti
žymos, atsižvelgiant į jų charakteristikas. Norėdami atskirti a , mums reikėtų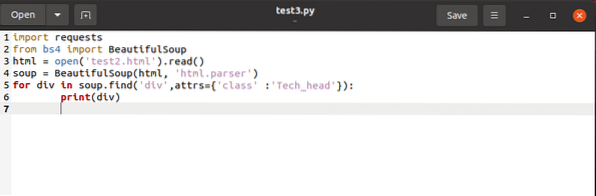
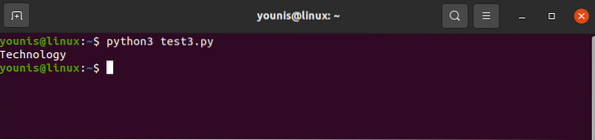
for div sriuboje.find_all ('div', attrs = 'class' = 'Tech_head'):
Tai atneša
žyma.Jūs gausite:
Technologija
Viskas be etikečių.
Galiausiai aptarsime, kaip pažymėti atributo vertę žymoje. Kode turėtų būti ši žyma:
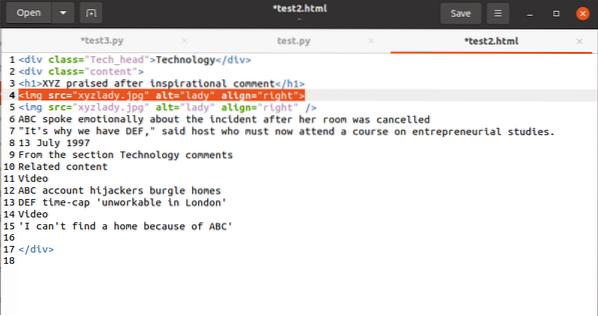

Norėdami naudoti vertę, susietą su src atributu, naudokite:
htmlcontent.rasti („img“) [„src“]O išeitis pasirodytų tokia:
"images_4 / a-pradedantiesiems-žiniatinklio vadovas su-python-and-beautiful-sriuba.JPG "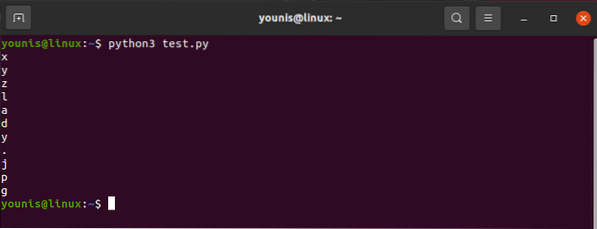
O berniuk, tai tikrai yra daugybė darbų!
Jei manote, kad jūsų žinios apie pitoną ar HTML yra nepakankamos arba jei jus tiesiog pribloškia žiniatinklio grandymas, nesijaudinkite.
Jei esate verslas, kuriam reikia reguliariai gauti tam tikro tipo duomenis, bet pats negalite pats nuskaityti žiniatinklio, tai yra būdų, kaip išspręsti šią problemą. Bet žinok, kad tai kainuos šiek tiek pinigų. Galite rasti ką nors, kas jums užrašys, arba galite gauti aukščiausios kokybės duomenų paslaugą iš tokių svetainių kaip „Google“ ir „Twitter“, kad galėtų su jumis bendrinti duomenis. Jie dalijasi savo duomenų dalimis naudodami API, tačiau šie API skambučiai yra ribojami per dieną. Be to, tokios interneto svetainės gali labai apsaugoti jų duomenis. Paprastai daugelis tokių svetainių apskritai nesidalija jokiais savo duomenimis.
Paskutinės mintys
Prieš baigdami kalbėti, leiskite man jums pasakyti garsiai, jei tai dar nebuvo savaime suprantama; komandos find (), find_all () yra jūsų geriausi draugai, kai baigiate naudoti „BeautifulSoup“. Nors yra daug daugiau, kad padengtumėte pagrindinius duomenis, ieškančius „Python“, šio vadovo turėtų pakakti tiems, kurie tik pradeda.


