Apache Kafka
Norėdami pateikti aukšto lygio apibrėžimą, pateikime trumpą Apache Kafka apibrėžimą:
„Apache Kafka“ yra paskirstytas, atsparus trikdžiams, horizontaliai keičiamo dydžio įsipareigojimų žurnalas.
Tai buvo aukšto lygio žodžiai apie Apache Kafka. Leiskite mums išsamiai suprasti sąvokas čia.
- Paskirstyta: „Kafka“ dalija turimus duomenis į kelis serverius ir kiekvienas iš šių serverių gali apdoroti klientų užklausas dėl joje esančios duomenų dalies
- Atsparus gedimams: Kafka neturi vieno nesėkmės taško. „SPoF“ sistemoje, pavyzdžiui, „MySQL“ duomenų bazėje, jei duomenų bazę talpinantis serveris neveikia, programa įsukama. Sistemoje, kurioje nėra SPoF ir kurią sudaro keli mazgai, net jei didžioji sistemos dalis nukrenta, galutiniam vartotojui ji vis tiek yra tokia pati.
- Horizontaliai keičiamas: Šis nuskaitymas reiškia daugiau mašinų pridėjimą į esamą grupę. Tai reiškia, kad „Apache Kafka“ sugeba priimti daugiau mazgų savo klasteryje ir nepateikti prastovų reikalingiems sistemos naujovinimams. Peržiūrėkite žemiau esantį paveikslėlį, kad suprastumėte, kokio tipo skandinimo sąvokos yra:
- Įvykdyti žurnalą: Įsipareigojimų žurnalas yra duomenų struktūra, kaip ir susietasis sąrašas. Jis prideda bet kokius pranešimus ir visada palaiko jų tvarką. Duomenų negalima ištrinti iš šio žurnalo, kol nepasiekiamas nurodytas tų duomenų laikas.
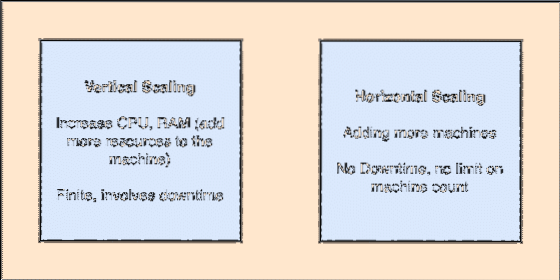
Vertikalus ir horizontalus skriejimas
„Apache Kafka“ tema yra tarsi eilė, kurioje saugomi pranešimai. Šie pranešimai saugomi konfigūruojamą laiką ir pranešimas neištrinamas, kol pasiekiamas šis laikas, net jei jį vartojo visi žinomi vartotojai.
„Kafka“ yra keičiamo dydžio, nes vartotojai iš tikrųjų saugo, kad jų gautas pranešimas paskutinį kartą yra „kompensuojama“ vertė. Pažvelkime į figūrą, kad tai geriau suprastume: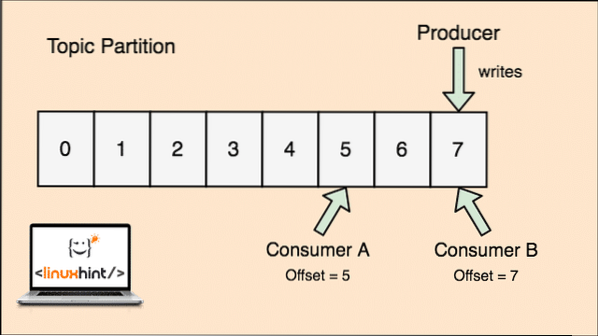
Temos skaidymas ir vartotojų kompensavimas „Apache Kafka“
Darbo su Apache Kafka pradžia
Norėdami pradėti naudoti „Apache Kafka“, jis turi būti įdiegtas kompiuteryje. Norėdami tai padaryti, skaitykite „Apache Kafka“ diegimas „Ubuntu“.
Įsitikinkite, kad turite aktyvų „Kafka“ diegimą, jei norite išbandyti pavyzdžius, kuriuos pateikiame vėliau pamokoje.
Kaip tai veikia?
Su Kafka Prodiuseris programos skelbia žinutes kuris atvažiuoja prie Kafkos Mazgas o ne tiesiogiai Vartotojui. Iš šio „Kafka“ mazgo pranešimus vartoja Vartotojas programos.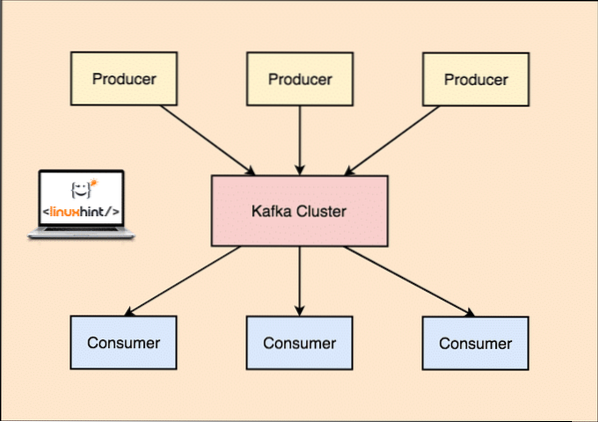
„Kafka“ gamintojas ir vartotojas
Kadangi viena tema vienu metu gali gauti daug duomenų, kad „Kafka“ būtų horizontaliai keičiama, kiekviena tema yra suskirstyta į pertvaros ir kiekvienas skaidinys gali gyventi bet kurioje klasterio mazgo mašinoje. Pabandykime tai pateikti:
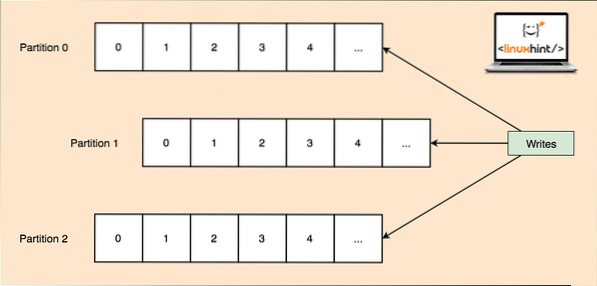
Temos pertvaros
Vėlgi, „Kafka Broker“ nesurašo, kuris vartotojas sunaudojo kiek duomenų paketų. Tai yra vartotojų atsakomybė sekti suvartotus duomenis.
Atkaklumas diskui
„Kafka“ neišsaugo pranešimų įrašų, kuriuos gauna iš gamintojų, diske ir nelaiko jų atmintyje. Gali kilti klausimas, kaip tai daro viską įmanoma ir greita? Tai lėmė kelios priežastys, dėl kurių tai optimalus būdas tvarkyti pranešimų įrašus:
- Kafka vadovaujasi pranešimų įrašų grupavimo protokolu. Gamintojai gamina pranešimus, kurie laikomi diske didelėmis dalimis, o vartotojai šiuos pranešimų įrašus taip pat naudoja dideliais linijiniais gabalais.
- Priežastis, kad diskas rašo linijiškai, yra ta, kad tai leidžia greitai skaityti dėl labai sumažėjusio linijinio disko skaitymo laiko.
- Linijinio disko operacijas optimizuoja Operacinės sistemos taip pat naudojant užrašymas ir skaityti į priekį.
- Šiuolaikinė OS taip pat naudoja Talpinimas tai reiškia, kad jie talpina kai kuriuos disko duomenis į laisvą RAM.
- Kadangi Kafka išlaiko duomenis vienodais standartiniais duomenimis visame sraute nuo gamintojo iki vartotojo, jis naudoja nulinės kopijos optimizavimas procesą.
Duomenų platinimas ir replikavimas
Kaip mes anksčiau ištyrėme, kad tema yra padalinta į skaidinius, kiekvienas pranešimų įrašas yra replikuojamas keliuose klasterio mazguose, siekiant išlaikyti kiekvieno įrašo tvarką ir duomenis tuo atveju, jei vienas iš mazgų miršta.
Nors skaidinys atkartojamas keliuose mazguose, vis tiek yra pertvaros vadovas mazgas, per kurį programos skaito ir rašo duomenis apie temą, o vadovas atkartoja kitų mazgų duomenis, kurie vadinami pasekėjų tos pertvaros.
Jei pranešimų įrašo duomenys yra labai svarbūs programai, garantija, kad pranešimų įrašas bus saugus viename iš mazgų, gali būti padidintas padidinant replikacijos koeficientas klasterio.
Kas yra „Zookeeper“?
„Zookeeper“ yra labai tolerantiška gedimams, paskirstyta raktų vertės parduotuvė. „Apache Kafka“ labai priklauso nuo „Zookeeper“, kad saugotų klasterių mechaniką, pvz., Širdies plakimą, naujienų / konfigūracijų platinimą ir kt.).
Tai leidžia „Kafka“ brokeriams užsiprenumeruoti save ir žinoti, kai įvyko koks nors pasikeitimas dėl skaidinio vadovo ir mazgo paskirstymo.
Gamintojų ir vartotojų programos tiesiogiai bendrauja su „Zookeeper“ programa žinoti, kuris mazgas yra temos skaidinio vadovas, kad jie galėtų skaityti ir rašyti iš skaidinio vadovo.
Srautas
Srauto procesorius yra pagrindinis „Kafka“ sankaupos komponentas, kuris nuolat priima pranešimų įrašų duomenų srautą iš įvesties temų, apdoroja šiuos duomenis ir sukuria duomenų srautą iki išvesties temų, kurios gali būti bet kokios, nuo šiukšliadėžės iki duomenų bazės.
Visiškai įmanoma atlikti paprastą apdorojimą tiesiogiai naudojant gamintojo / vartotojo API, nors sudėtingam apdorojimui, pvz., Srautų sujungimui, „Kafka“ teikia integruotą „Stream“ API biblioteką, tačiau atkreipkite dėmesį, kad ši API skirta naudoti mūsų pačių kodų bazėje ir to nereikia “ t paleisti pas brokerį. Tai veikia panašiai kaip vartotojų API ir padeda mums išplėsti srauto apdorojimo darbą keliose programose.
Kada vartoti Apache Kafka?
Kaip mes studijavome ankstesniuose skyriuose, „Apache Kafka“ gali būti naudojama daugeliui pranešimų įrašų, kurie gali priklausyti beveik begaliniam mūsų sistemų temų skaičiui, tvarkyti.
„Apache Kafka“ yra idealus kandidatas, kai reikia naudotis paslauga, kuri gali leisti mums vadovautis įvykių architektūra mūsų programose. Taip yra dėl duomenų patvarumo, gedimams atsparios ir labai paskirstytos architektūros galimybių, kai kritinės programos gali pasikliauti jos našumu.
Dėl keičiamo mastelio ir paskirstytos „Kafka“ architektūros labai lengva integruotis su mikroservisomis ir leidžia programai atsiriboti nuo daugybės verslo logikų.
Naujos temos kūrimas
Mes galime sukurti bandomąją temą testavimas „Apache Kafka“ serveryje naudodami šią komandą:
Kurkite temą
sudo kafka-temos.sh --create --zookeeper localhost: 2181 - replikacijos koeficientas 1--1 skirsnis - temų testavimas
Štai ką mes grąžiname naudodami šią komandą: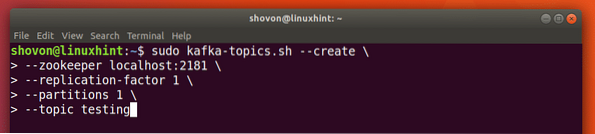
Sukurkite naują „Kafka“ temą
Bus sukurta testavimo tema, kurią galime patvirtinti minėta komanda:
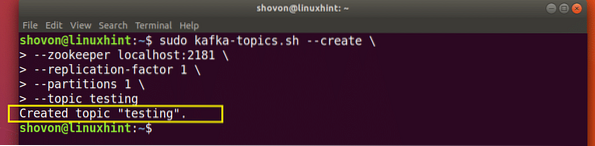
„Kafka“ temos kūrimo patvirtinimas
Pranešimų rašymas temoje
Kaip mes anksčiau tyrėme, viena iš „Apache Kafka“ esančių API yra Gamintojo API. Šią API naudosime kurdami naują pranešimą ir skelbdami ką tik sukurtą temą:
Rašyti pranešimą į temą
sudo kafka-konsolės gamintojas.sh - broker-list localhost: 9092 - temų testavimasPažiūrėkime šios komandos išvestį:
Paskelbkite pranešimą „Kafka“ temoje
Kai paspausime klavišą, pamatysime naują rodyklės (>) ženklą, o tai reiškia, kad dabar galime pateikti duomenis:

Rašyti žinutę
Tiesiog įveskite ką nors ir paspauskite, kad pradėtumėte naują eilutę. Įvedžiau 3 teksto eilutes:
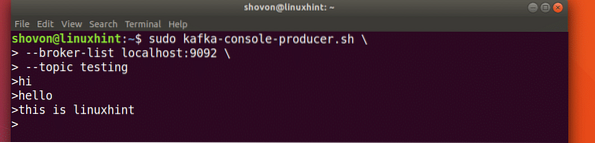
Pranešimų skaitymas iš temos
Dabar, kai mes paskelbėme pranešimą savo sukurtoje „Kafka“ temoje, šis pranešimas bus kurį laiką konfigūruojamas. Dabar galime jį perskaityti naudodami Vartotojo API:
Pranešimų skaitymas iš temos
sudo kafka-konsolė-vartotojas.sh - zookeeper localhost: 2181 --temos testavimas - nuo pat pradžių
Štai ką mes grąžiname naudodami šią komandą:
Komanda perskaityti pranešimą iš „Kafka“ temos
Mes galėsime pamatyti pranešimus ar eilutes, kurias parašėme naudodami „Producer“ API, kaip parodyta žemiau:
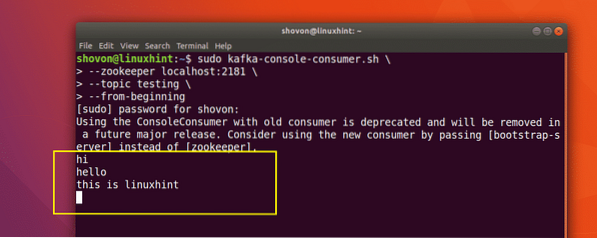
Jei parašysime dar vieną naują pranešimą naudodami „Producer“ API, jis taip pat bus nedelsiant parodytas vartotojo pusėje:
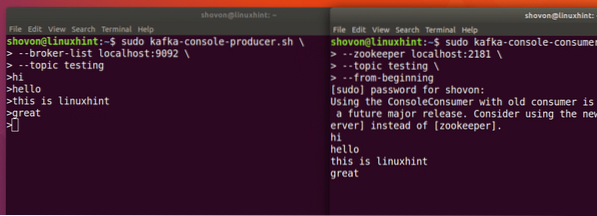
Skelbti ir vartoti tuo pačiu metu
Išvada
Šioje pamokoje mes apžvelgėme, kaip pradedame naudoti „Apache Kafka“, kuris yra puikus „Message Broker“ ir gali veikti kaip specialus duomenų atkūrimo padalinys.


