
Kai pradėjau dirbti su mašininio mokymosi problemomis, tada jaučiuosi panika, kurį algoritmą turėčiau naudoti? Arba kurį lengva pritaikyti? Jei esate panašus į mane, šis straipsnis gali padėti sužinoti apie dirbtinį intelektą ir mašininio mokymosi algoritmus, metodus ar metodus, kaip išspręsti netikėtas ar net tikėtinas problemas.
Mašininis mokymasis yra tokia galinga dirbtinio intelekto technika, kuri gali efektyviai atlikti užduotį nenaudodama jokių aiškių nurodymų. ML modelis gali pasimokyti iš savo duomenų ir patirties. Mašininio mokymosi programos yra automatinės, tvirtos ir dinamiškos. Sukurti keli algoritmai, skirti spręsti šį dinamišką realaus gyvenimo problemų pobūdį. Apskritai yra trijų tipų mašininio mokymosi algoritmai, tokie kaip prižiūrimas mokymas, neprižiūrimas mokymasis ir mokymasis sustiprinti.
Geriausi dirbtinio intelekto ir mašininio mokymosi algoritmai
Tinkamos mašininio mokymosi technikos ar metodo pasirinkimas yra viena iš pagrindinių užduočių kuriant dirbtinio intelekto ar mašininio mokymosi projektą. Kadangi yra keli algoritmai, jie visi turi savo privalumų ir naudingumo. Žemiau mes pasakojame apie 20 mašininio mokymosi algoritmų, skirtų tiek pradedantiesiems, tiek profesionalams. Taigi, pažvelkime.
1. Naivusis Bayesas
Naivus Bayes klasifikatorius yra tikimybinis klasifikatorius, pagrįstas Bayeso teorema, darant prielaidą, kad požymiai yra nepriklausomi. Šios funkcijos skiriasi kiekvienoje programoje. Tai yra vienas patogiausių mašininio mokymosi metodų pradedantiesiems.
Naivusis Bayesas yra sąlyginis tikimybės modelis. Atsižvelgiant į probleminį egzempliorių, kurį reikia klasifikuoti, vaizduojantį vektorių x = (xi … Xn) atspindėdamas kai kuriuos n požymius (nepriklausomus kintamuosius), jis priskiria dabartiniams egzempliorių tikimybėms kiekvienam iš K potencialių rezultatų:
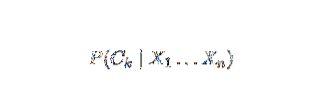 Pirmiau pateiktos formuluotės problema yra ta, kad jei požymių skaičius n yra reikšmingas arba jei elementas gali įgyti daugybę reikšmių, tada tokio modelio remtis tikimybės lentelėmis yra neįmanoma. Todėl mes pertvarkome modelį, kad jis būtų lengviau valdomas. Naudojant Bayeso teoremą, sąlyginė tikimybė gali būti parašyta kaip,
Pirmiau pateiktos formuluotės problema yra ta, kad jei požymių skaičius n yra reikšmingas arba jei elementas gali įgyti daugybę reikšmių, tada tokio modelio remtis tikimybės lentelėmis yra neįmanoma. Todėl mes pertvarkome modelį, kad jis būtų lengviau valdomas. Naudojant Bayeso teoremą, sąlyginė tikimybė gali būti parašyta kaip,
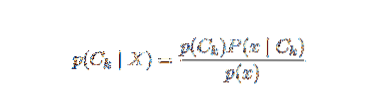
Naudojant Bajeso tikimybės terminologiją, aukščiau pateiktą lygtį galima parašyti taip:
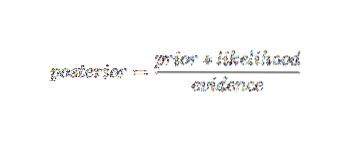
Šis dirbtinio intelekto algoritmas naudojamas klasifikuojant tekstą, t.e., nuotaikų analizė, dokumentų skirstymas į kategorijas, šlamšto filtravimas ir naujienų klasifikavimas. Ši mašininio mokymosi technika gerai veikia, jei įvesties duomenys skirstomi į iš anksto nustatytas grupes. Be to, tam reikia mažiau duomenų nei logistinei regresijai. Jis pranoksta įvairias sritis.
2. Palaikykite „Vector Machine“
„Support Vector Machine“ (SVM) yra vienas iš plačiausiai naudojamų prižiūrimų mašinų mokymosi algoritmų teksto klasifikavimo srityje. Šis metodas taip pat naudojamas regresijai. Tai taip pat gali būti vadinama „Support Vector Networks“. „Cortes & Vapnik“ sukūrė šį metodą dvejetainiai klasifikacijai. Prižiūrimas mokymosi modelis yra mašininio mokymosi metodas, kuris daro išvadą iš pažymėtų mokymo duomenų.
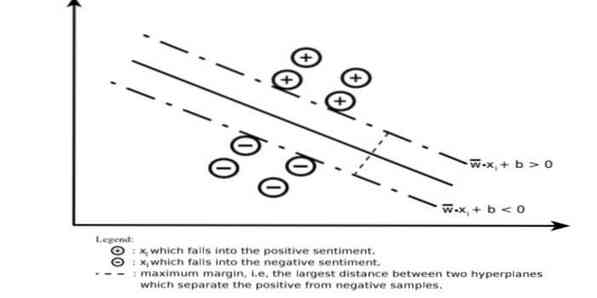
Atraminio vektoriaus mašina labai aukštoje ar begalinės dimensijos srityje konstruoja hiper plokštumą ar hiper plokštumų rinkinį. Jis apskaičiuoja tiesinio atskyrimo paviršių su didžiausia marža tam tikram treniruočių rinkiniui.
Tik įvesties vektorių pogrupis turės įtakos maržos pasirinkimui (paveikslėlyje apskritas); tokie vektoriai vadinami atramos vektoriais. Kai nėra linijinio atskyrimo paviršiaus, pavyzdžiui, esant triukšmingiems duomenims, tinkami yra SVM algoritmai su kintamuoju kintamuoju. Šis klasifikatorius bando padalyti duomenų erdvę naudodamas linijinius ar netiesinius skirtingų klasių atribojimus.
SVM buvo plačiai naudojamas modelio klasifikavimo problemoms spręsti ir netiesinei regresijai. Be to, tai yra vienas iš geriausių būdų, kaip atlikti automatinį teksto klasifikavimą. Geriausias dalykas šiame algoritme yra tai, kad jis nedaro jokių tvirtų duomenų prielaidų.
Norėdami įdiegti „Support Vector Machine“: duomenų mokslo bibliotekos „Python- SciKit Learn“, PyML, SVMStruktūrinis „Python“, LIBSVM ir duomenų mokslo bibliotekos „R- Klar“, e1071.
3. Tiesinė regresija
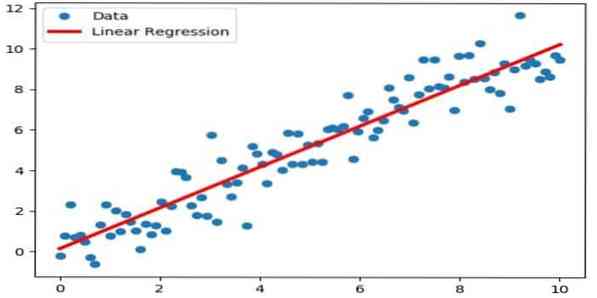
Linijinė regresija yra tiesioginis metodas, naudojamas modeliuojant priklausomo kintamojo ir vieno ar daugiau nepriklausomų kintamųjų santykį. Jei yra vienas nepriklausomas kintamasis, tada jis vadinamas paprasta tiesine regresija. Jei yra daugiau nei vienas nepriklausomas kintamasis, tai vadinama daugine tiesine regresija.
Ši formulė naudojama vertinant realias vertes, tokias kaip namų kaina, skambučių skaičius, bendras pardavimas, remiantis nuolatiniais kintamaisiais. Čia santykis tarp nepriklausomų ir priklausomų kintamųjų nustatomas pritaikant geriausią eilutę. Ši geriausiai tinkanti linija yra žinoma kaip regresijos tiesė ir ją vaizduoja tiesinė lygtis
Y = a * X + b.
čia,
- Y - priklausomas kintamasis
- a - nuolydis
- X - nepriklausomas kintamasis
- b - perimti
Šį mašininio mokymosi metodą lengva naudoti. Tai vykdoma greitai. Tai gali būti naudojama versle prognozuojant pardavimus. Jis taip pat gali būti naudojamas vertinant riziką.
4. Logistinė regresija
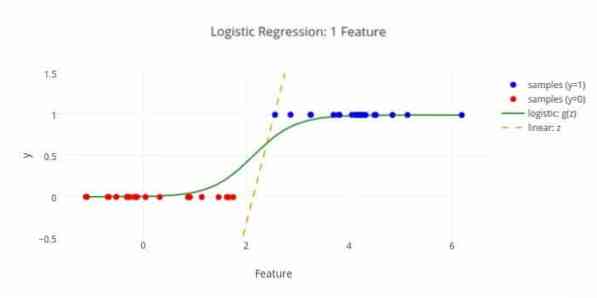
Čia yra dar vienas mašininio mokymosi algoritmas - logistinė regresija arba logito regresija, kuri naudojama norint įvertinti atskiras vertes (dvejetainės vertės, tokios kaip 0/1, taip / ne, tiesa / klaidinga), remiantis tam tikru nepriklausomo kintamojo rinkiniu. Šio algoritmo užduotis yra numatyti įvykio tikimybę, pritaikant duomenis logito funkcijai. Jo išvesties vertės yra nuo 0 iki 1.
Formulę galima naudoti įvairiose srityse, tokiose kaip mašininis mokymasis, mokslinė disciplina ir medicinos sritis. Jis gali būti naudojamas numatant tam tikros ligos pavojų, atsižvelgiant į pastebėtas paciento savybes. Logistinė regresija gali būti naudojama numatant kliento norą pirkti produktą. Ši mašininio mokymosi technika naudojama prognozuojant orus, norint numatyti lietaus tikimybę.
Logistinę regresiją galima suskirstyti į tris rūšis -
- Dvejetainė logistinė regresija
- Daugiavardė logistinė regresija
- Eilinė logistinė regresija
Logistinė regresija nėra tokia sudėtinga. Be to, jis yra tvirtas. Jis gali valdyti netiesinius efektus. Tačiau jei treniruotės duomenys yra negausūs ir matmenų, šis ML algoritmas gali būti per didelis. Jis negali numatyti nuolatinių rezultatų.
5. K-artimiausias kaimynas (KNN)
K-artimiausias kaimynas (kNN) yra gerai žinomas statistinis klasifikavimo metodas, kuris daugelį metų buvo plačiai ištirtas ir anksti pritaikytas kategorizavimo užduotims. Tai veikia kaip neparametrinė klasifikavimo ir regresijos problemų metodika.
Šis AI ir ML metodas yra gana paprastas. Jis nustato bandomojo dokumento kategoriją t pagal k dokumentų rinkinio balsavimą, kurie yra artimiausi t atstumu, paprastai Euklido atstumu. Pagrindinė kNN klasifikatoriaus bandymo dokumento t taisyklė yra:
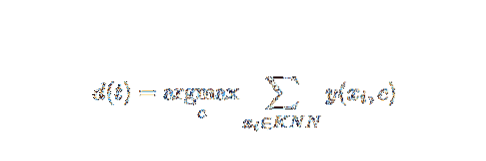
Jei y (xi, c) yra dvejetainė mokymo dokumento xi klasifikavimo funkcija (kuri grąžina 1 reikšmę, jei xi pažymėta c, arba 0 kitaip), ši taisyklė pažymi t kategoriją, kuriai suteikiama daugiausia balsų k - artimiausias rajonas.
Mes galime susieti KNN su savo realiu gyvenimu. Pvz., Jei norėtumėte sužinoti keletą žmonių, apie kuriuos neturite jokios informacijos, galbūt norėtumėte apsispręsti dėl jo artimų draugų ir dėl to draugų ratų, kuriuose jis persikelia, ir gauti prieigą prie jo informacijos. Šis algoritmas yra brangus skaičiavimams.
6. K reiškia
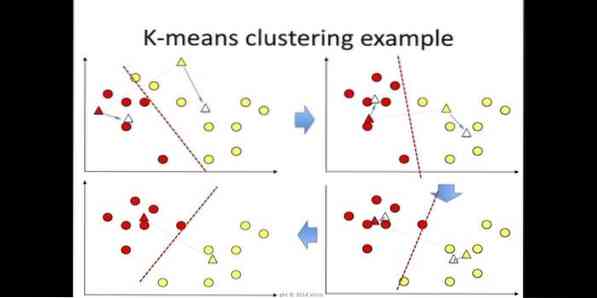
k-reiškia klasteris yra neprižiūrimo mokymosi metodas, prieinamas duomenų klasterių analizei klasteriuose. Šio algoritmo tikslas yra suskirstyti n stebėjimą į k grupes, kur kiekvienas stebėjimas priklauso artimiausiam klasterio vidurkiui. Šis algoritmas naudojamas rinkos segmentavimui, kompiuterio matymui ir astronomijai tarp daugelio kitų sričių.
7. Sprendimų medis
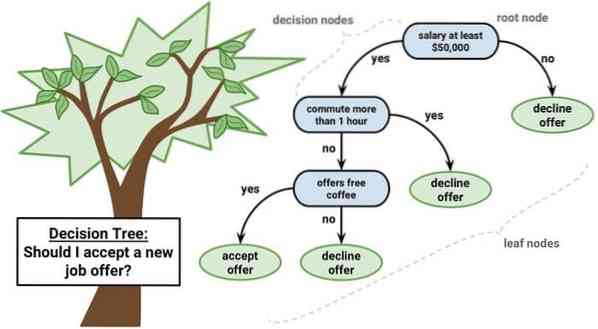
Sprendimų medis yra sprendimų palaikymo įrankis, kuris naudoja grafinį vaizdą, t.e., medžių pavidalo grafikas ar sprendimų modelis. Jis dažniausiai naudojamas analizuojant sprendimus, taip pat populiarus įrankis mokantis mašinoje. Sprendimų medžiai naudojami operacijų tyrimams ir operacijų valdymui.
Ji turi schemą, panašią į schemą, kurioje kiekvienas vidinis mazgas reiškia atributo „testą“, kiekvienas šaka - testo rezultatą, o kiekvienas lapo mazgas - klasės etiketę. Maršrutas nuo šaknies iki lapo yra žinomas kaip klasifikavimo taisyklės. Jis susideda iš trijų tipų mazgų:
- Sprendimo mazgai: paprastai vaizduojami kvadratais,
- Galimybės mazgai: paprastai vaizduojami apskritimais,
- Pabaigos mazgai: paprastai vaizduojami trikampiais.
Sprendimų medį lengva suprasti ir interpretuoti. Jis naudoja baltos dėžės modelį. Be to, jis gali būti derinamas su kitomis sprendimų priėmimo technologijomis.
8. Atsitiktinis miškas
Atsitiktinis miškas yra populiari ansamblio mokymosi technika, kuri treniruočių metu sukonstruoja daugybę sprendimų medžių ir pateikia kategoriją, kuri yra kiekvieno medžio kategorijų (klasifikacija) arba vidutinė prognozė (regresija) režimas.
Šio mašininio mokymosi algoritmo vykdymo laikas yra greitas ir jis gali dirbti su nesubalansuotais ir trūkstamais duomenimis. Tačiau kai mes jį panaudojome regresijai, jis negali nuspėti už treniruotės duomenų ribų ir gali per daug sutalpinti duomenis.
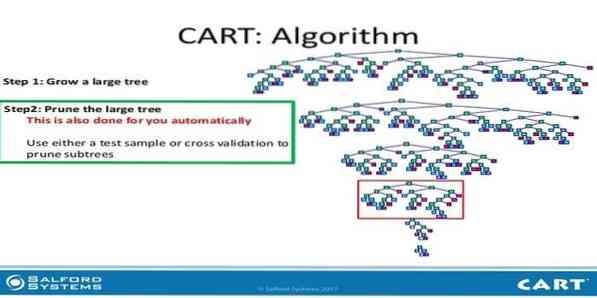
9. KREPŠELIS
Klasifikacijos ir regresijos medis (CART) yra vienos rūšies sprendimų medis. Sprendimų medis veikia kaip rekursinis skaidymo metodas, o CART padalija kiekvieną įvesties mazgą į du antrinius mazgus. Kiekviename sprendimų medžio lygyje algoritmas nustato sąlygą - kurį kintamąjį ir lygį naudoti įvesties mazgui padalyti į du antrinius mazgus.
CART algoritmo žingsniai pateikti toliau:
- Paimkite įvesties duomenis
- Geriausias Splitas
- Geriausias kintamasis
- Padalinkite įvesties duomenis į kairįjį ir dešinįjį mazgus
- Tęskite 2–4 veiksmus
- Sprendimų medžio genėjimas
10. Apriori mašininio mokymosi algoritmas

Apriori algoritmas yra kategorizavimo algoritmas. Ši mašininio mokymosi technika naudojama rūšiuojant didelius duomenų kiekius. Jis taip pat gali būti naudojamas stebėti, kaip vystosi santykiai ir kuriamos kategorijos. Šis algoritmas yra neprižiūrimas mokymosi metodas, kuris generuoja asociacijos taisykles iš tam tikro duomenų rinkinio.
Apriori mašininio mokymosi algoritmas veikia kaip:
- Jei daiktų rinkinys įvyksta dažnai, tada visi elementų rinkinio pogrupiai taip pat vyksta dažnai.
- Jei elementų rinkinys įvyksta retai, tada visi elementų rinkinio viršsustatymai taip pat pasitaiko retai.
Šis ML algoritmas naudojamas įvairiose programose, pavyzdžiui, norint nustatyti nepageidaujamas reakcijas į vaistus, rinkos krepšelio analizei ir automatinio užbaigimo programoms. Tai paprasta įgyvendinti.
11. Pagrindinių komponentų analizė (PCA)
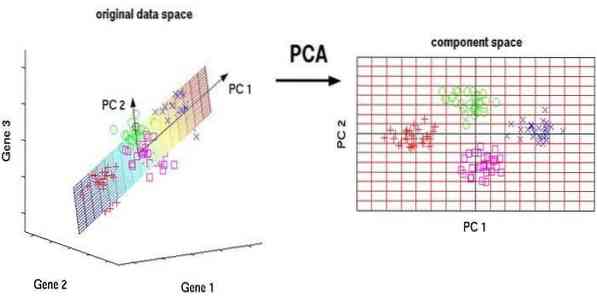
Pagrindinio komponento analizė (PCA) yra neprižiūrimas algoritmas. Naujos savybės yra stačios, tai reiškia, kad jos nėra susijusios. Prieš atlikdami PCA, visada turėtumėte normalizuoti savo duomenų rinkinį, nes transformacija priklauso nuo masto. Jei to nepadarysite, svarbiausiose skalėse esančios savybės dominuos naujuose pagrindiniuose komponentuose.
PCA yra universali technika. Šis algoritmas yra be vargo ir lengvai įgyvendinamas. Jis gali būti naudojamas apdorojant vaizdus.
12. „CatBoost“
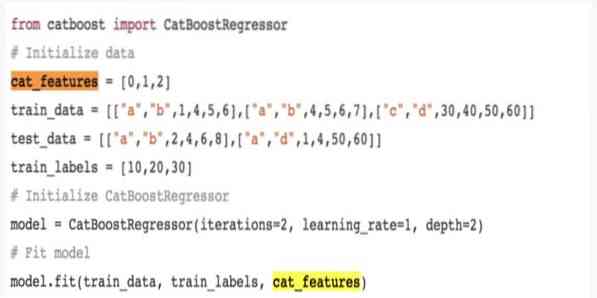
„CatBoost“ yra atviro šaltinio mašinų mokymosi algoritmas, gaunamas iš „Yandex“. Pavadinimas „CatBoost“ kilęs iš dviejų žodžių „Category“ ir „Boosting“.„Tai gali derinti su giluminėmis mokymosi sistemomis, t.e., „Google“ „TensorFlow“ ir „Apple Core ML“. „CatBoost“ gali dirbti su daugybe duomenų tipų, kad išspręstų kelias problemas.
13. 3 kartotinis dichotomizatorius (ID3)
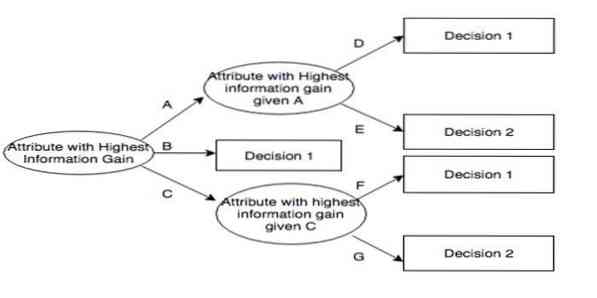
„Iterative Dichotomiser 3“ (ID3) yra sprendimų medžio mokymosi algoritminė taisyklė, kurią pateikė Rossas Quinlanas ir kuri naudojama sprendimų medžiui pateikti iš duomenų rinkinio. Tai yra C4 pirmtakas.5 algoritminę programą ir yra naudojamas mašininio mokymosi ir kalbinio bendravimo proceso srityse.
ID3 gali per daug atitikti treniruočių duomenis. Šią algoritminę taisyklę sudėtingiau naudoti nenutrūkstamiems duomenims. Tai negarantuoja optimalaus sprendimo.
14. Hierarchinis klasteris
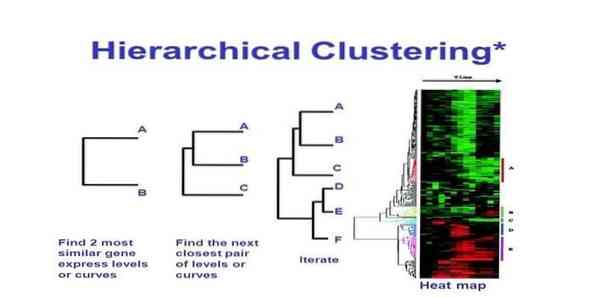
Hierarchinis grupavimas yra klasterių analizės būdas. Atliekant hierarchinį grupavimą, duomenų iliustravimui yra sukurtas klasterių medis (dendrograma). Pagal hierarchinį grupavimą kiekviena grupė (mazgas) susieja dvi ar daugiau teisių perėmėjų grupių. Kiekviename klasterio medžio mazge yra panašių duomenų. Mazgai grupuojami diagramoje šalia kitų panašių mazgų.
Algoritmas
Šį mašininio mokymosi metodą galima suskirstyti į du modelius - iki dugno arba iš viršaus į apačią:
Iš apačios į viršų (hierarchinis aglomeracinis klasteris, RVB)
- Šios mašininio mokymosi technikos pradžioje kiekvieną dokumentą paimkite kaip vieną grupę.
- Naujoje grupėje sujungė du elementus vienu metu. Tai, kaip sujungiami sujungimai, apima skaičiuojamąjį skirtumą tarp kiekvienos sujungtos poros ir dėl to alternatyvių pavyzdžių. Yra daugybė galimybių tai padaryti. Kai kurie iš jų yra:
a. Visiškas susiejimas: Tolimiausios poros panašumas. Vienas apribojimas yra tas, kad pašaliniai rodikliai gali sukelti artimų grupių susijungimą vėliau, nei yra optimalu.
b. Vienkartinis sujungimas: Artimiausios poros panašumas. Tai gali sukelti priešlaikinį susijungimą, nors šios grupės yra gana skirtingos.
c. Grupės vidurkis: panašumas tarp grupių.
d. Centroido panašumas: kiekviena iteracija sujungia grupes su svarbiausiu panašiu centriniu tašku.
- Kol visi elementai nesusijungia į vieną grupę, vyksta susiejimo procesas.
Iš viršaus į apačią (susiskaldžiusios grupės)
- Duomenys pradedami kombinuota grupe.
- Grupė pagal tam tikrą panašumą dalijasi į dvi skirtingas dalis.
- Grupės vėl ir vėl dalijasi į dvi, kol grupėse yra tik vienas duomenų taškas.
15. Nugaros dauginimas
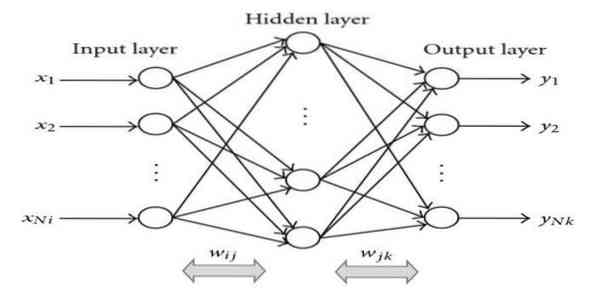
Nugaros sklaida yra prižiūrimas mokymosi algoritmas. Šis ML algoritmas yra iš ANN (dirbtinių neuronų tinklų) srities. Šis tinklas yra daugiasluoksnis perdavimo tinklas. Šiuo metodu siekiama suprojektuoti tam tikrą funkciją, modifikuojant vidinius įvesties signalų svorius, kad gautų norimą išėjimo signalą. Jis gali būti naudojamas klasifikacijai ir regresijai.

Atgalinio sklidimo algoritmas turi tam tikrų pranašumų, t.e., ją lengva įgyvendinti. Algoritme naudojamą matematinę formulę galima pritaikyti bet kuriam tinklui. Skaičiavimo laikas gali būti sutrumpintas, jei svoris yra mažas.
Atgalinio sklidimo algoritmas turi tam tikrų trūkumų, pavyzdžiui, jis gali būti jautrus triukšmingiems duomenims ir pašaliniams parametrams. Tai visiškai matricos principas. Faktinis šio algoritmo veikimas visiškai priklauso nuo įvesties duomenų. Išvestis gali būti ne skaitmeninė.
16. „AdaBoost“
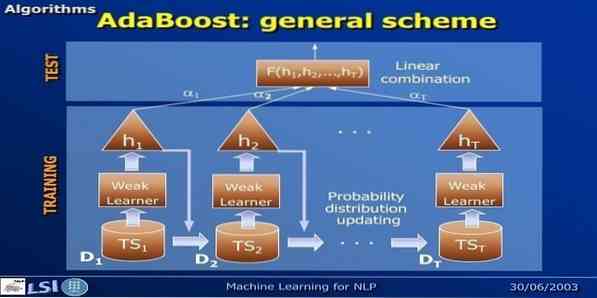
„AdaBoost“ reiškia „Adaptive Boosting“, mašininio mokymosi metodą, kurį atstovauja Yoav Freund ir Robert Schapire. Tai yra meta-algoritmas, kurį galima integruoti su kitais mokymosi algoritmais, siekiant pagerinti jų našumą. Šis algoritmas yra greitas ir paprastas naudoti. Tai gerai veikia su dideliais duomenų rinkiniais.
17. Gilus mokymasis
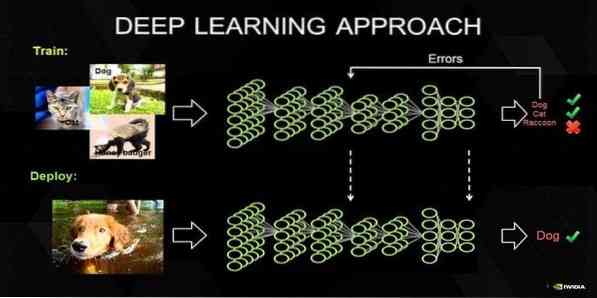
Gilus mokymasis yra metodų rinkinys, įkvėptas žmogaus smegenų mechanizmo. Du pagrindiniai giluminiai mokymai, t.e., Konvoliuciniai neuroniniai tinklai (CNN) ir pasikartojantys neuroniniai tinklai (RNN) naudojami teksto klasifikacijoje. Taip pat naudojami gilaus mokymosi algoritmai, tokie kaip „Word2Vec“ ar „GloVe“, kad gautų aukšto rango vektorinius žodžių atvaizdavimus ir pagerintų klasifikatorių tikslumą, kuris mokomas naudojant tradicinius mašininio mokymosi algoritmus.
Šiam mašininio mokymosi metodui reikia daug mokymo pavyzdžio, o ne tradicinių mašininio mokymosi algoritmų, t.e., mažiausiai milijonai paženklintų pavyzdžių. Priešingai, tradicinės mašininio mokymosi technikos pasiekia tikslų ribą visur, kur pridedant daugiau mokymo pavyzdžių, jų tikslumas apskritai nepagerėja. Giliai mokantis klasifikatoriai lenkia geresnius rezultatus, turėdami daugiau duomenų.
18. Gradiento stiprinimo algoritmas

Gradiento didinimas yra mašininio mokymosi metodas, naudojamas klasifikacijai ir regresijai. Tai yra vienas iš galingiausių būdų sukurti nuspėjamąjį modelį. Gradiento didinimo algoritme yra trys elementai:
- Nuostolių funkcija
- Silpnas mokinys
- Priedų modelis
19. „Hopfield“ tinklas
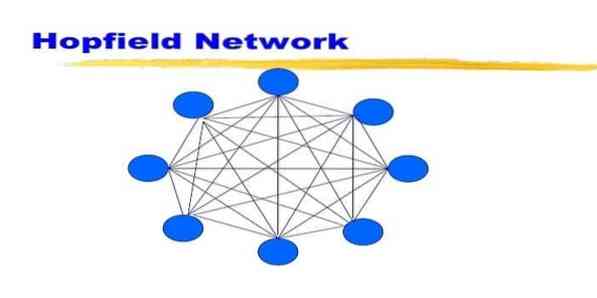
„Hopfield“ tinklas yra vienos rūšies pasikartojantis dirbtinis neuroninis tinklas, kurį 1982 m. Pateikė Johnas Hopfieldas. Šis tinklas siekia išsaugoti vieną ar daugiau modelių ir priminti visus modelius, pagrįstus daline įvestimi. „Hopfield“ tinkle visi mazgai yra tiek įėjimai, tiek išėjimai ir visiškai sujungti.
20. C4.5

C4.5 yra sprendimų medis, kurį išrado Rossas Quinlanas. Tai atnaujinta ID3 versija. Ši algoritminė programa apima keletą pagrindinių atvejų:
- Visi sąraše esantys pavyzdžiai priklauso panašiai kategorijai. Tai sukuria sprendimų medžio lapų mazgą, kuriame sakoma, kad reikia nuspręsti dėl tos kategorijos.
- Naudojant laukiamą klasės vertę, medžio aukštyje sukuriamas sprendimo mazgas.
- Naudojant laukiamą vertę, medžio aukštyje sukuriamas sprendimo mazgas.
Baigiančios mintys
Labai svarbu naudoti tinkamą algoritmą, pagrįstą jūsų duomenimis ir domenu, kuriant efektyvų mašininio mokymosi projektą. Be to, norint išsiaiškinti kritinį kiekvieno mašininio mokymosi algoritmo skirtumą, reikia išspręsti „kai pasirenku kurį iš jų.„Taikant mašininio mokymosi metodą, mašina ar įrenginys išmoko per mokymosi algoritmą. Aš tvirtai tikiu, kad šis straipsnis padeda suprasti algoritmą. Jei turite kokių nors pasiūlymų ar užklausų, klauskite. Skaityk toliau.


