„pip“ įdiekite „BeautifulSoup4“
Norėdami patikrinti, ar diegimas buvo sėkmingas, suaktyvinkite interaktyvų „Python“ apvalkalą ir importuokite „BeautifulSoup“. Jei klaidos neatsiranda, tai reiškia, kad viskas gerai. Jei nežinote, kaip tai padaryti, įveskite šias komandas savo terminale.
$ python„Python 3“.5.2 (numatytasis, 2017 m. Rugsėjo 14 d., 22:51:06)
[PĮB 5.4.0 20160609] „Linux“
Norėdami gauti daugiau informacijos, įveskite „pagalba“, „autorių teisės“, „kreditai“ arba „licencija“.
>>> importuoti bs4
Norėdami dirbti su „BeautifulSoup“ biblioteka, turite perduoti HTML. Dirbdami su tikromis svetainėmis, naudodami užklausų biblioteką galite gauti tinklalapio HTML. Užklausų bibliotekos diegimas ir naudojimas nepatenka į šio straipsnio taikymo sritį, tačiau jūs galite lengvai susipažinti su dokumentais, kuriuos naudoti yra gana paprasta. Šiame straipsnyje paprasčiausiai ketiname naudoti html python eilutėje, kurią mes vadiname HTML.
html = "" "[apsaugotas el. paštu]
pparkerworks.com
"" "
Norėdami naudoti „beautifulsoup“, importuojame ją į kodą naudodami toliau pateiktą kodą:
iš bs4 importuoti BeautifulSoupTaip „BeautifulSoup“ būtų įtraukta į mūsų vardų sritį ir mes galime ją naudoti analizuodami savo eilutę.
sriuba = BeautifulSoup (html, "lxml")Dabar, sriuba yra bs4 tipo „BeautifulSoup“ objektas.Mes galime atlikti visas „BeautifulSoup“ operacijas sriubakintamasis.
Pažvelkime į kai kuriuos dalykus, kuriuos galime padaryti naudodami „BeautifulSoup“ dabar.
PADARYTI BĖLĄ, GRAŽŲ
Kai „BeautifulSoup“ analizuoja HTML, tai paprastai nėra geriausiais formatais. Tarpai yra gana siaubingi. Žymas sunku rasti. Čia yra vaizdas, parodantis, kaip jie atrodys, kai gausite spausdinti sriuba:
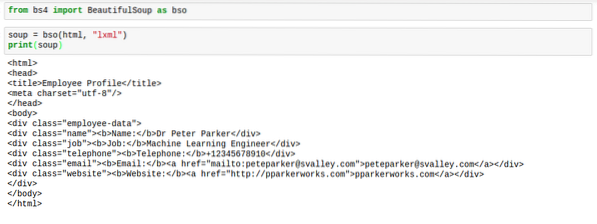
Tačiau tam yra sprendimas. Sprendimas suteikia html puikų tarpą, todėl viskas atrodo gerai. Šis sprendimas pelnytai vadinamas „pagražinti„.
Tiesa, dažniausiai negalėsite naudotis šia funkcija; tačiau kartais gali būti, kad neturite prieigos prie žiniatinklio naršyklės tikrinimo elemento įrankio. Tais laikais, kai ištekliai yra riboti, prettify metodas jums bus labai naudingas.
Štai kaip jūs jį naudojate:
sriuba.pagražinti ()Žymėjimas atrodys tinkamai išdėstytas, kaip ir toliau pateiktame paveikslėlyje:
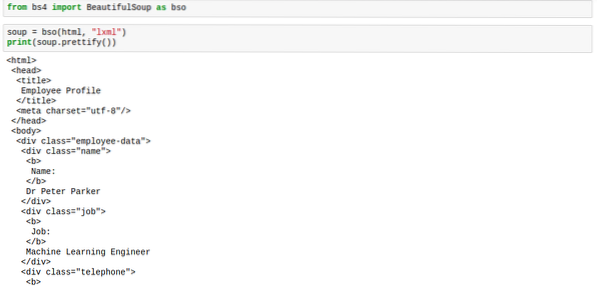
Sriubai pritaikius prettify metodą, rezultatas nebėra bs4 tipo.Graži sriuba. Dabar rezultatas yra „unicode“ tipas. Tai reiškia, kad jūs negalite taikyti kitų „BeautifulSoup“ metodų, tačiau pačiai sriubai tai neturi įtakos, todėl mes esame saugūs.
RASTI MĖGSTAMAS ŽYMES
HTML sudaro žymos. Juose saugomi visi jo duomenys, o tarp viso to netvarkos slypi mums reikalingi duomenys. Iš esmės tai reiškia, kad radę tinkamas žymas galime gauti tai, ko mums reikia.
Taigi, kaip rasti tinkamas žymas? Mes naudojame „BeautifulSoup“ paieškos ir suradimo metodus.
Štai kaip jie veikia:
The rasti metodas ieško pirmosios žymos su reikalingu pavadinimu ir grąžina bs4 tipo objektą.elementas.Žyma.
The rasti_visi metodas, ieško visų žymų su reikalingu žymos pavadinimu ir grąžina jas kaip bs4 tipo sąrašą.elementas.Rezultato rinkinys. Visi sąrašo elementai yra bs4 tipo.elementas.Žyma, kad galėtume atlikti indeksavimą sąraše ir tęsti savo gražios sriubos tyrimą.
Pažiūrėkime kodą. Suraskime visas div žymas:
sriuba.rasti („div“)Mes gautume tokį rezultatą:
Patikrinę html kintamąjį pastebėsite, kad tai yra pirmoji div žyma.
sriuba.find_all („div“)Mes gautume tokį rezultatą:
[[apsaugotas el. paštu]
pparkerworks.com
Pateikiamas sąrašas. Pavyzdžiui, jei norite trečiosios „div“ žymos, paleidžiate šį kodą:
sriuba.find_all („div“) [2]Tai grąžintų:
RASTI MŪSŲ MĖGSTAMŲ ŽYMŲ PRIEDUS
Dabar, kai pamatėme, kaip gauti mėgstamiausias žymas, kaip gauti jų atributus?
Galbūt šiuo metu galvojate: „Kam mums reikia atributų?„. Na, daugeliu atvejų dauguma mums reikalingų duomenų bus el. Pašto adresai ir svetainės. Tokie duomenys tinklalapiuose paprastai būna susieti su nuorodomis atribute „href“.
Ištraukę reikiamą žymą, naudodami „find“ arba „find_all“ metodus, atributus galime gauti taikydami pritraukia. Tai grąžins atributo žodyną ir jo vertę.
Pavyzdžiui, norėdami gauti el. Pašto atributą, gauname žymes, kurios supa reikalingą informaciją, ir atlikite šiuos veiksmus.
sriuba.find_all („a“) [0].pritraukiaTai grąžintų šį rezultatą:
'href': 'mailto: [apsaugotas el. paštu]'Tas pats dalykas, susijęs su svetainės atributu.
sriuba.find_all („a“) [1].pritraukiaTai grąžintų šį rezultatą:
'href': 'http: // pparkerworks.com„Grąžintos vertės yra žodynai, o norint gauti raktus ir reikšmes, gali būti taikoma įprasta žodyno sintaksė.
PAMATYKIME TĖVUS IR VAIKUS
Visur yra žymos. Kartais norime sužinoti, kas yra vaikų žymos ir kokia yra pagrindinė žyma.
Jei dar nežinote, kas yra pagrindinė ir antrinė žyma, turėtų pakakti šio trumpo paaiškinimo: tėvų žyma yra tiesioginė išorinė žyma, o vaikas yra tiesioginė vidinė žyma.
Pažvelgus į mūsų HTML, „body“ žyma yra visų „div“ žymių pagrindinė žyma. Be to, paryškinta žyma ir inkaro žyma yra „div“ žymų vaikai, kai taikoma, nes ne visos div žymos turi inkaro žymes.
Taigi pagrindinę žymą galime pasiekti paskambinę findParent metodas.
sriuba.rasti („div“).„findParent“ ()Tai grąžins visą kūno žymą:
[apsaugotas el. paštu]
pparkerworks.com
Norėdami gauti ketvirtosios div žymos vaikams žymą, mes vadiname rastiVaikai metodas:
sriuba.find_all ("div") [4].rastiVaikai ()Pateikiama:
[Interneto svetainė:, pparkerworks.com]KAS JO MUMS?
Naršydami tinklalapiuose, ekrane matome ne visur žymas. Viskas, ką matome, yra skirtingų žymų turinys. Ką daryti, jei norime žymos turinio, o ne visi kampiniai skliaustai daro gyvenimą nepatogiu? Tai nėra sunku, viskas, ką mes padarytume, yra paskambinti get_text metodas pasirinktoje žymoje ir gauname tekstą žymoje, o jei žymoje yra kitų žymų, ji taip pat gauna jų teksto reikšmes.
Štai pavyzdys:
sriuba.rasti („kūnas“).get_text ()Tai grąžina visas teksto reikšmes turinio žymoje:
Vardas: dr. Peteris ParkerisDarbas: mašinų mokymosi inžinierius
Telefonas: +12345678910
El. Paštas: [el. Pašto saugoma]
Tinklalapis: pparkerworks.com
IŠVADA
Štai ką mes turime už šį straipsnį. Tačiau vis dar yra kitų įdomių dalykų, kuriuos galima padaryti su gražia sriuba. Galite patikrinti dokumentus arba naudoti rež. („BeautfulSoup“) interaktyviame apvalkale, kad pamatytumėte veiksmų, kuriuos galima atlikti su „BeautifulSoup“ objektu, sąrašą. Šiandien viskas iš manęs, kol vėl parašysiu.


